python, 전처리, 통계, 가설검정, 기계학습, 회귀, 분류, 군집, 모델 학습, 모델 평가
통계적 추론의 출발점은 데이터가 어떤 확률분포에서 생성되었는지를 이해하는 것이다. 확률분포는 데이터의 불확실성을 수학적으로 모델링하며, 이를 통해 데이터의 패턴을 파악하고 미래를 예측할 수 있다. 또한 표본과 모집단의 관계를 이해하면, 제한된 데이터로부터 전체에 대한 결론을 도출할 수 있다. 이 장에서는 대표적인 확률분포와 표본 개념, 그리고 통계적 추론의 핵심인 중심극한정리를 학습한다.
예제: 데이터 로드
import seaborn as snsimport pandas as pdimport numpy as npimport matplotlib.pyplot as plt# 데이터 로드df = sns.load_dataset("penguins").dropna()print("데이터 크기:", df.shape)print("\n수치형 변수:")print(df.select_dtypes(include=[np.number]).columns.tolist())
데이터 크기: (333, 7)
수치형 변수:
['bill_length_mm', 'bill_depth_mm', 'flipper_length_mm', 'body_mass_g']
11.1 확률분포의 개념
확률분포(Probability Distribution)는 확률변수가 취할 수 있는 값과 그 값이 나타날 확률의 구조를 나타낸다. 모든 통계 분석은 데이터가 특정 확률분포를 따른다는 가정에서 출발한다.
확률분포의 핵심 개념
개념
설명
예시
확률변수 (Random Variable)
결과가 확률적으로 결정되는 변수
주사위 눈, 키, 몸무게
확률질량함수 (PMF)
이산형 변수의 확률 분포
P(X = k)
확률밀도함수 (PDF)
연속형 변수의 확률 밀도
f(x)
누적분포함수 (CDF)
특정 값 이하일 확률
P(X ≤ x)
기댓값 (Expected Value)
평균적으로 기대되는 값
E[X] = μ
분산 (Variance)
값의 퍼짐 정도
Var[X] = σ²
확률분포의 분류
확률분포는 변수의 유형에 따라 크게 두 가지로 구분된다.
이산형 확률분포: 셀 수 있는 값들의 분포 (예: 0, 1, 2, 3, …)
연속형 확률분포: 실수 구간의 모든 값을 가질 수 있는 분포 (예: 키, 몸무게)
11.2 연속형 확률분포 (Continuous Distributions)
연속형 확률분포는 실수 구간의 모든 값을 가질 수 있는 변수의 분포이다. 특정 점에서의 확률은 0이며, 구간의 확률을 확률밀도함수(PDF)의 적분으로 계산한다.
11.2.1 대표적인 연속형 분포
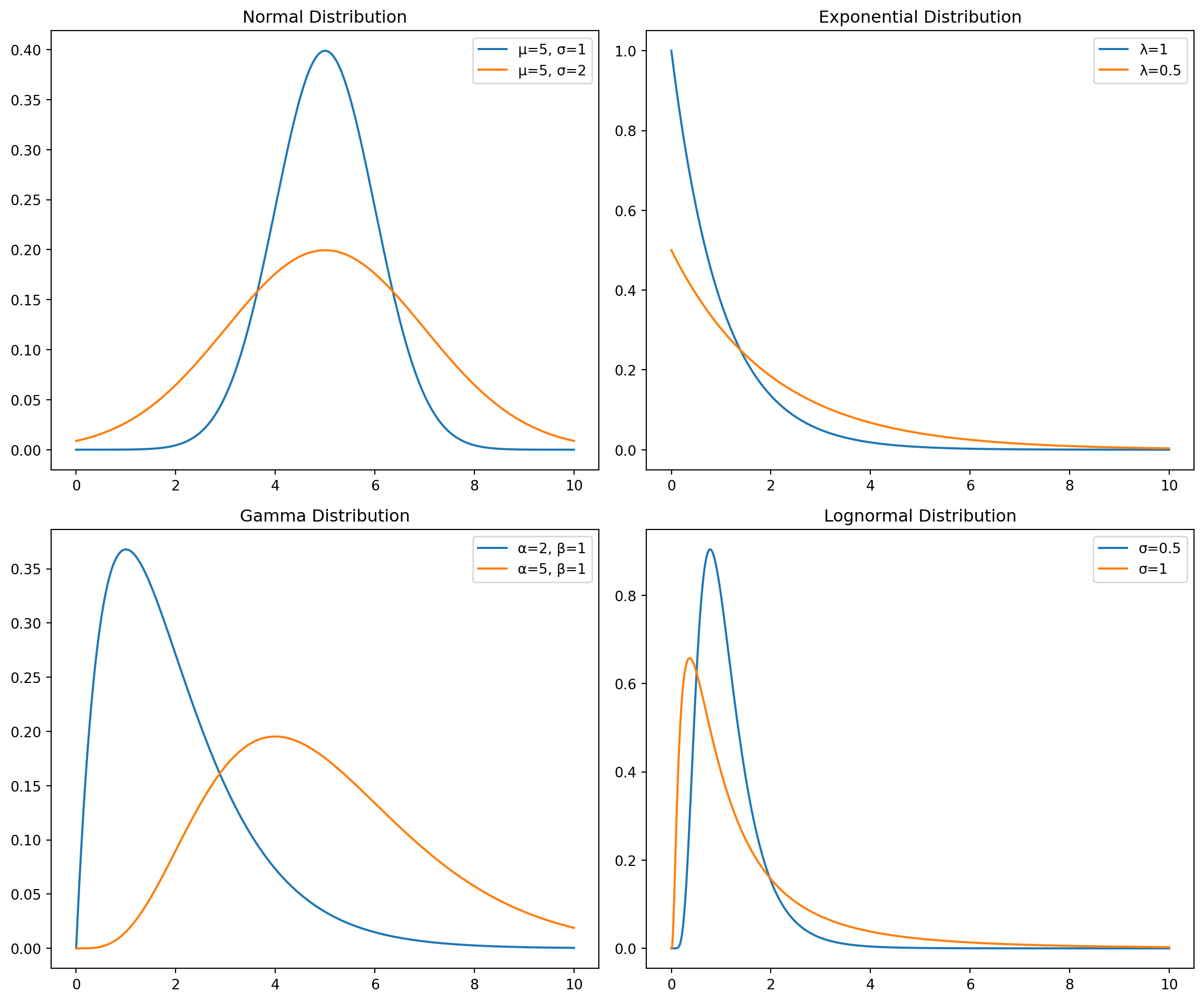
연속형 분포 비교
분포
형태
특징
파라미터
사용 예시
정규분포 (Normal)
종 모양, 대칭
중심극한정리, 자연 현상
μ (평균), σ² (분산)
신체 측정값, 시험 점수
지수분포 (Exponential)
오른쪽 꼬리
무기억성, 대기 시간
λ (비율)
고장 시간, 서비스 대기
감마분포 (Gamma)
비대칭, 양수
지수분포의 일반화
α (형태), β (척도)
생존 시간, 보험 청구액
로그정규분포 (Lognormal)
오른쪽 꼬리
로그 변환 시 정규분포
μ (로그 평균), σ² (로그 분산)
소득, 주택 가격, 입자 크기
t-분포 (Student’s t)
정규와 유사, 두꺼운 꼬리
작은 표본 추론
ν (자유도)
소표본 가설검정
카이제곱분포 (Chi-squared)
오른쪽 치우침
정규분포 제곱합
k (자유도)
분산 검정, 적합도 검정
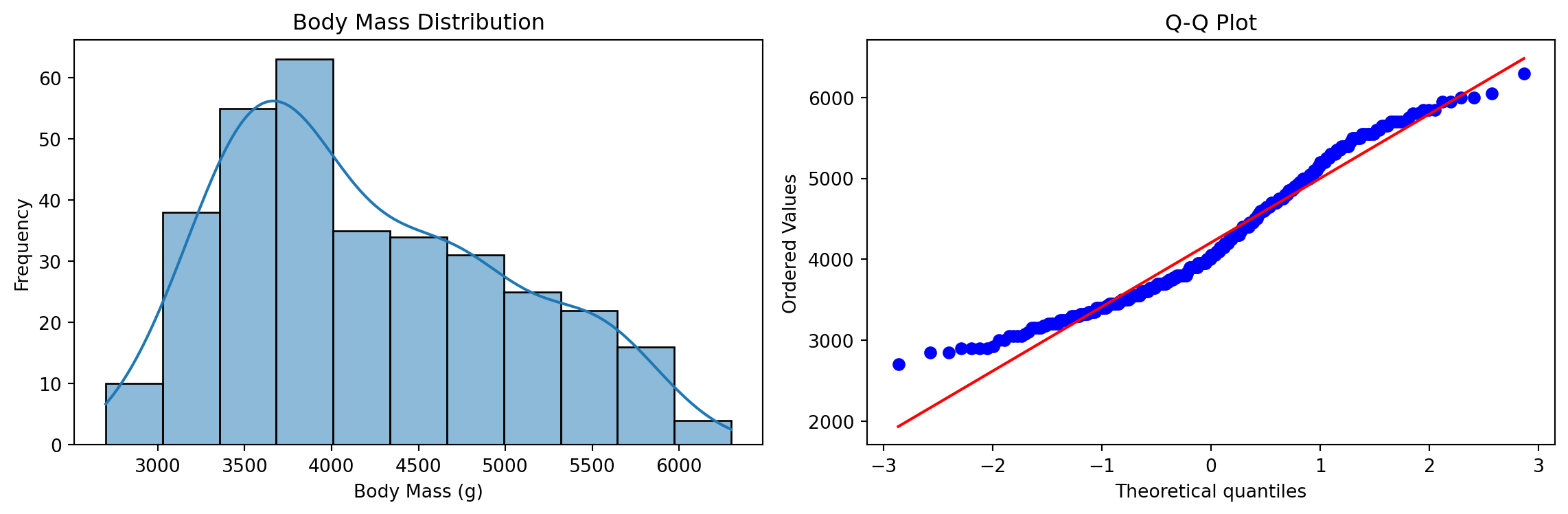
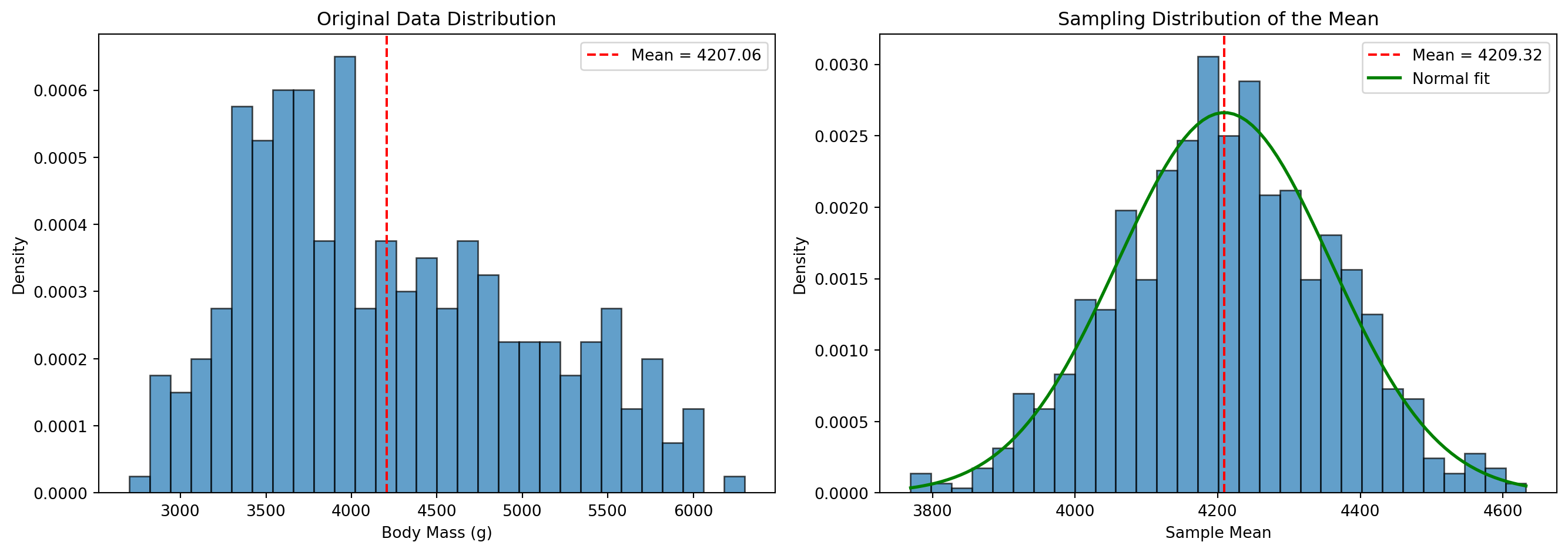
11.2.2 정규분포 (Normal Distribution)
정규분포는 자연 현상에서 가장 흔히 나타나는 분포로, 평균을 중심으로 좌우 대칭인 종 모양을 띤다.
# 극단적으로 왜곡된 분포 (지수분포) 생성exponential_data = np.random.exponential(scale=2, size=10000)# 원본 데이터 분포fig, axes = plt.subplots(1, 2, figsize=(14, 5))axes[0].hist(exponential_data, bins=50, density=True, alpha=0.7, edgecolor='black')axes[0].set_title("Original Exponential Distribution")axes[0].set_xlabel("Value")axes[0].set_ylabel("Density")# 표본 평균 분포 (n=30)sample_means_exp = []for _ inrange(1000): sample = np.random.choice(exponential_data, size=30, replace=True) sample_means_exp.append(sample.mean())axes[1].hist(sample_means_exp, bins=30, density=True, alpha=0.7, edgecolor='black')x = np.linspace(min(sample_means_exp), max(sample_means_exp), 100)axes[1].plot(x, stats.norm.pdf(x, np.mean(sample_means_exp), np.std(sample_means_exp)), 'r-', linewidth=2, label='Normal fit')axes[1].set_title("Sampling Distribution (n=30)")axes[1].set_xlabel("Sample Mean")axes[1].set_ylabel("Density")axes[1].legend()plt.tight_layout()plt.show()print(f"원본 데이터 왜도: {stats.skew(exponential_data):.3f}")print(f"표본 평균 왜도: {stats.skew(sample_means_exp):.3f}")
원본 데이터 왜도: 1.985
표본 평균 왜도: 0.433
원본 데이터는 극도로 왜곡되어 있지만, 표본 평균의 분포는 정규분포에 매우 가깝다는 것을 확인할 수 있다.
11.8 요약
이 장에서는 확률분포와 표본의 개념, 그리고 통계적 추론의 핵심인 중심극한정리를 학습했다. 주요 내용은 다음과 같다.
확률분포 요약
구분
대표 분포
특징
주요 사용처
연속형
정규분포
대칭, 종 모양
신체 측정, 자연 현상
연속형
지수분포, 감마분포
양수, 오른쪽 치우침
대기 시간, 생존 분석
연속형
로그정규분포
로그 변환 시 정규
소득, 가격, 크기
이산형
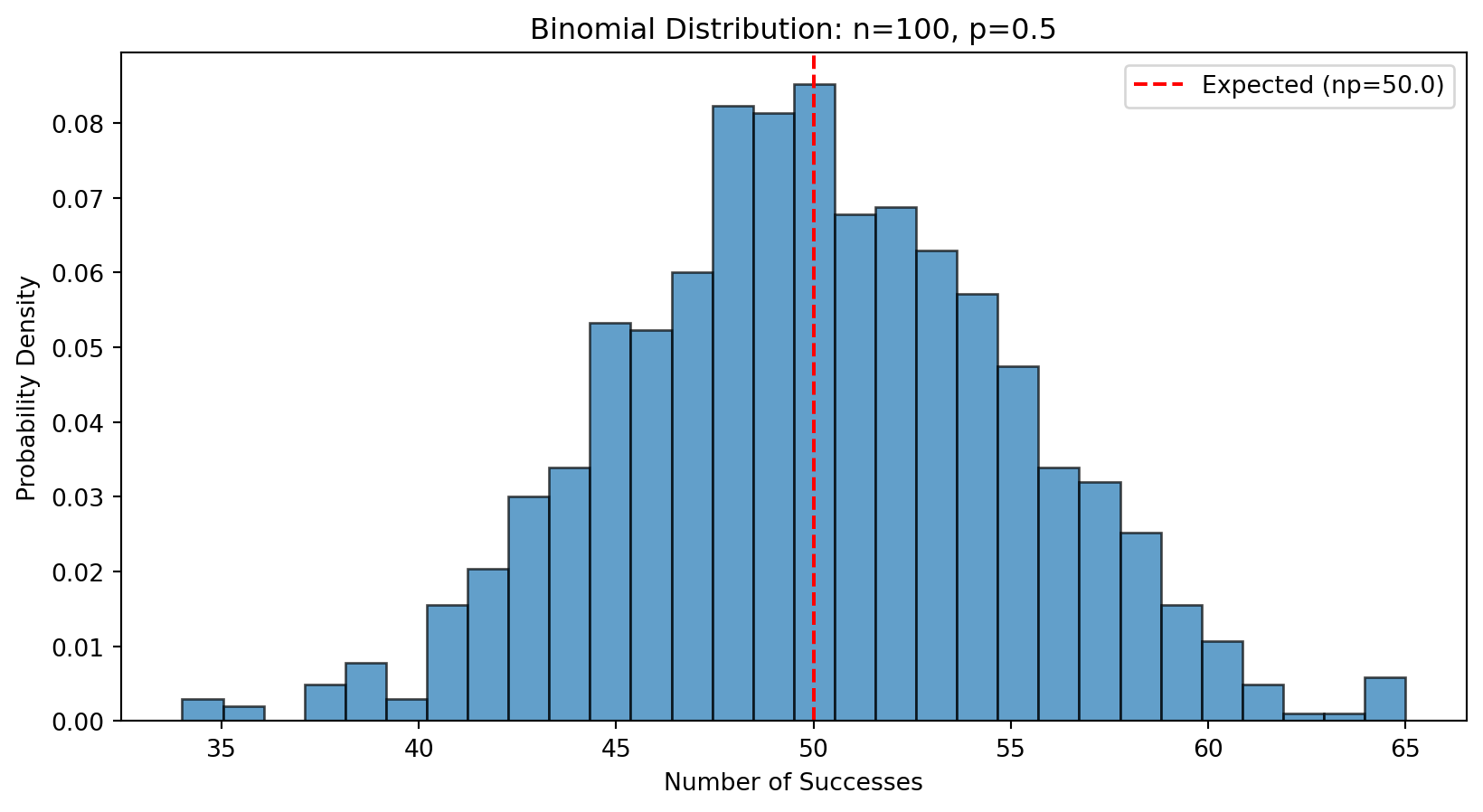
이항분포
성공 횟수
불량품 개수, 설문 응답
이산형
포아송분포
발생 횟수
고객 방문, 사고 건수
표본과 모집단
모집단: 연구 대상 전체 (파라미터: μ, σ²)
표본: 모집단에서 추출한 일부 (통계량: x̄, s²)
표본 추출의 목적: 비용 절감, 실용성, 시의성
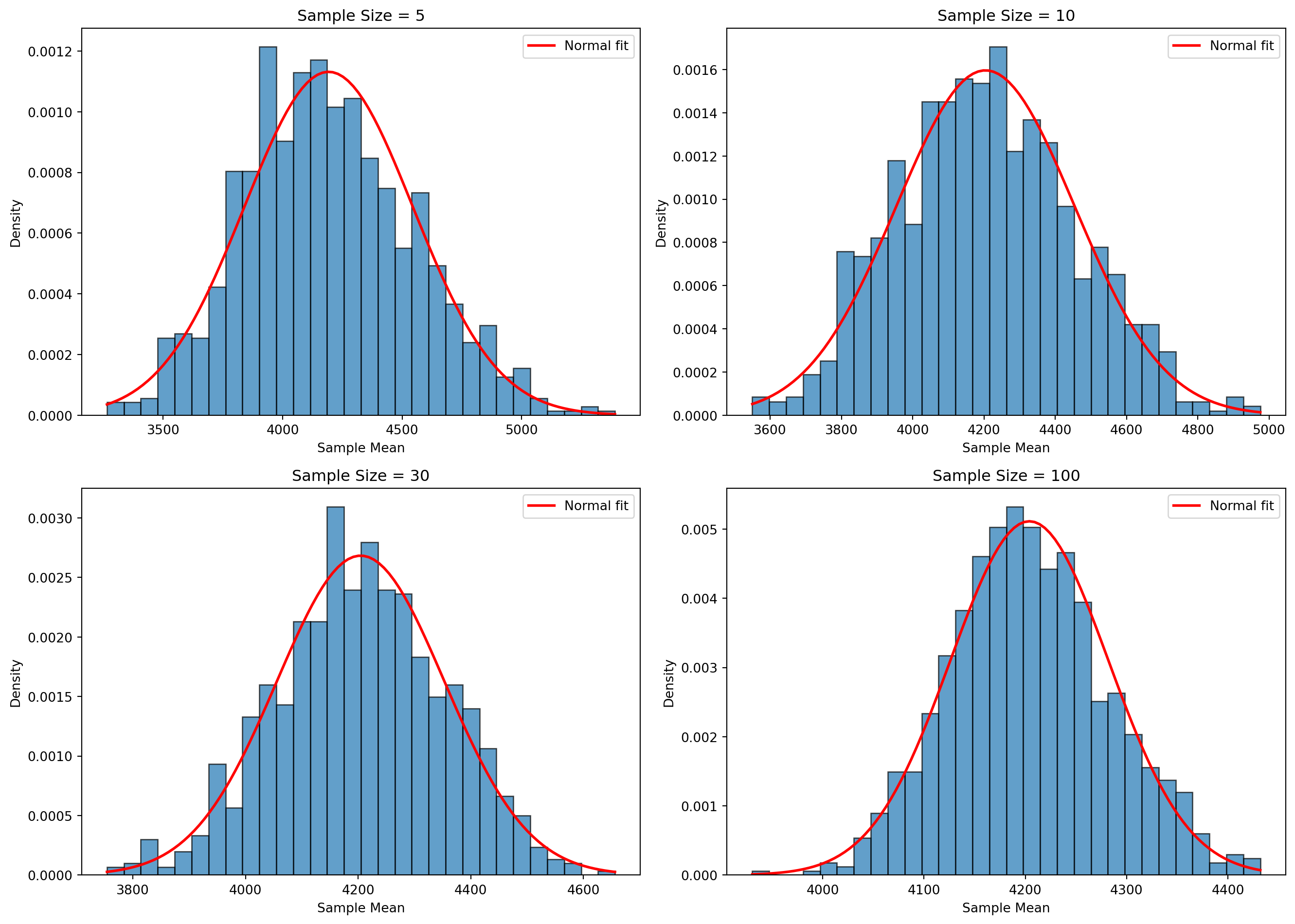
중심극한정리 핵심
내용: 표본 크기가 충분히 크면 표본 평균은 정규분포에 수렴
조건: n ≥ 30 (일반적), 독립성, 동일 분포
의미: 모집단 분포와 무관하게 정규분포 기반 추론 가능
적용: t-검정, ANOVA, 신뢰구간, 회귀분석 등
실무 적용
데이터 분포 확인: 히스토그램, Q-Q 플롯, 정규성 검정
표본 설계: 적절한 표본 크기와 추출 방법 선택
통계 분석: 중심극한정리를 바탕으로 가설검정과 신뢰구간 구성
결과 해석: 표본 통계량으로 모집단 파라미터 추정
확률분포와 표본의 개념은 통계학과 데이터 분석의 기초이다. 중심극한정리를 이해하면 제한된 표본으로부터 모집단에 대한 타당한 결론을 도출할 수 있으며, 이는 모든 통계적 추론의 출발점이 된다. 다음 장에서는 이러한 이론을 바탕으로 실제 가설검정과 신뢰구간 추정을 학습할 것이다.