분산분석(ANOVA: Analysis of Variance)은 세 개 이상 집단의 평균을 동시에 비교하는 통계적 방법이다. 이름은 분산분석이지만 실제 관심 대상은 집단 간 평균 차이이며, 분산을 이용하여 평균 차이를 검정한다는 점에서 이러한 명칭이 붙었다. ANOVA는 t-검정을 여러 번 반복하는 대신 전체 유의수준을 유지하면서 다집단을 비교할 수 있어 실무에서 매우 중요하다. 이 장에서는 일원분산분석, 이원분산분석, 그리고 사후검정을 상세히 학습한다.
예제: 데이터 로드
import seaborn as snsimport pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom scipy import stats# 데이터 로드 = sns.load_dataset("penguins" )print ("데이터 크기:" , df.shape)print (" \n 범주형 변수:" , df.select_dtypes(include= ['object' , 'category' ]).columns.tolist())print ("연속형 변수:" , df.select_dtypes(include= [np.number]).columns.tolist())
데이터 크기: (344, 7)
범주형 변수: ['species', 'island', 'sex']
연속형 변수: ['bill_length_mm', 'bill_depth_mm', 'flipper_length_mm', 'body_mass_g']
분산분석의 기본 개념
분산분석은 전체 변동을 집단 간 변동과 집단 내 변동으로 분해하고, 집단 간 변동이 집단 내 변동에 비해 충분히 큰지를 검정한다.
분산분석의 핵심 원리
\[
\text{총 변동} = \text{집단 간 변동} + \text{집단 내 변동}
\]
\[
SST = SSB + SSW
\]
F-통계량
\[
F = \frac{MSB}{MSW} = \frac{SSB/(k-1)}{SSW/(N-k)}
\]
F 값이 클수록 집단 간 차이가 집단 내 변동에 비해 크다는 의미이다.
일원분산분석 (One-way ANOVA)
일원분산분석은 하나의 범주형 독립변수(요인)가 연속형 종속변수에 미치는 영향을 검정한다.
가설 설정
H₀: μ₁ = μ₂ = μ₃ = ⋯ = μₖ
H₁: 적어도 하나의 모평균이 다르다
예제: 데이터 준비
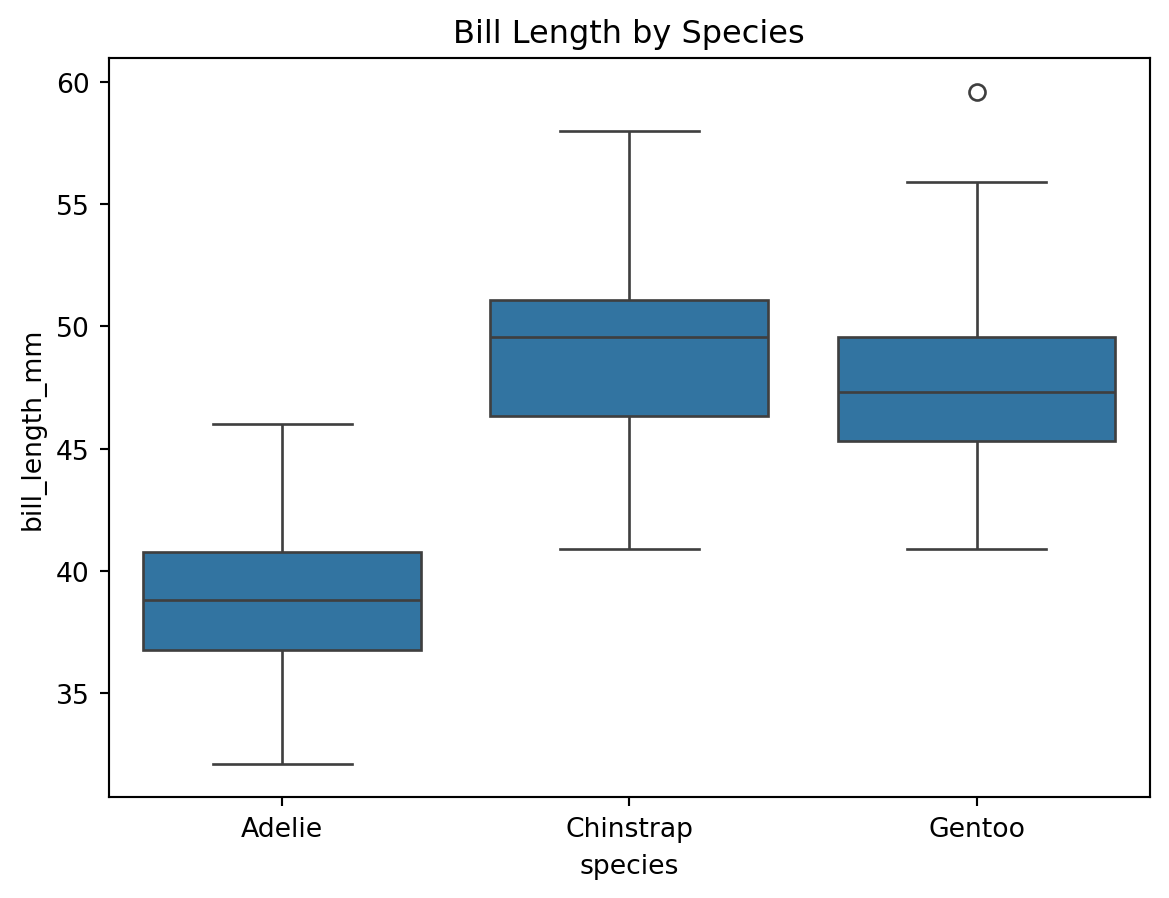
= df[["species" , "bill_length_mm" ]].dropna()print ("=== 집단별 기술 통계량 ===" )print (df_anova.groupby("species" )["bill_length_mm" ].describe())
=== 집단별 기술 통계량 ===
count mean std min 25% 50% 75% max
species
Adelie 151.0 38.791391 2.663405 32.1 36.75 38.80 40.750 46.0
Chinstrap 68.0 48.833824 3.339256 40.9 46.35 49.55 51.075 58.0
Gentoo 123.0 47.504878 3.081857 40.9 45.30 47.30 49.550 59.6
예제: 일원 ANOVA
from scipy.stats import f_oneway= ["species" ] == sp]["bill_length_mm" ]for sp in df_anova["species" ].unique()= f_oneway(* groups)print (" \n === 일원분산분석 ===" )print (f"F-통계량: { f_stat:.4f} " )print (f"p-value: { p_value:.4f} " )if p_value < 0.05 :print ("✓ 종에 따른 부리 길이 차이가 유의함 → 사후검정 필요" )
=== 일원분산분석 ===
F-통계량: 410.6003
p-value: 0.0000
✓ 종에 따른 부리 길이 차이가 유의함 → 사후검정 필요
이원분산분석 (Two-way ANOVA)
이원분산분석은 두 개의 범주형 독립변수와 그들의 상호작용 효과를 동시에 검정한다.
예제: 이원 ANOVA
= df[["species" , "sex" , "bill_length_mm" ]].dropna()import statsmodels.api as smfrom statsmodels.formula.api import ols= ols("bill_length_mm ~ C(species) + C(sex) + C(species):C(sex)" ,= df_two= sm.stats.anova_lm(model, typ= 2 )print (" \n === 이원분산분석 ===" )print (anova_table)
=== 이원분산분석 ===
sum_sq df F PR(>F)
C(species) 6975.591607 2.0 650.478579 1.059087e-114
C(sex) 1135.683888 1.0 211.806563 2.422971e-37
C(species):C(sex) 24.494427 2.0 2.284122 1.034865e-01
Residual 1753.338642 327.0 NaN NaN
사후검정 (Post-hoc Test)
예제: Tukey HSD
from statsmodels.stats.multicomp import pairwise_tukeyhsd= pairwise_tukeyhsd(= df_anova["bill_length_mm" ],= df_anova["species" ],= 0.05 print (" \n === Tukey HSD 사후검정 ===" )print (tukey)
=== Tukey HSD 사후검정 ===
Multiple Comparison of Means - Tukey HSD, FWER=0.05
=========================================================
group1 group2 meandiff p-adj lower upper reject
---------------------------------------------------------
Adelie Chinstrap 10.0424 0.0 9.0249 11.06 True
Adelie Gentoo 8.7135 0.0 7.8672 9.5598 True
Chinstrap Gentoo -1.3289 0.0089 -2.3819 -0.276 True
---------------------------------------------------------
예제: 시각화
= df_anova,= "species" ,= "bill_length_mm" "Bill Length by Species" )
가정 위배 시 대응
정규성 위배 → Kruskal-Wallis 검정
등분산성 위배 → Welch ANOVA
독립성 위배 → 반복측정 ANOVA
예제: Kruskal-Wallis (비모수)
from scipy.stats import kruskal= kruskal(* groups)print (f" \n === Kruskal-Wallis ===" )print (f"H = { h_stat:.4f} , p = { p_kw:.4f} " )
=== Kruskal-Wallis ===
H = 244.1367, p = 0.0000
요약
분산분석은 다집단의 평균을 동시에 비교하는 강력한 도구이다. 가정을 확인하고 사후검정을 통해 구체적인 차이를 파악하는 것이 중요하다.