python, 전처리, 통계, 가설검정, 기계학습, 회귀, 분류, 군집, 모델 학습, 모델 평가
데이터 분할(Data Splitting)과 검증(Validation)은 머신러닝 모델의 일반화 성능을 평가하는 핵심 과정이다. 모델의 성능은 알고리즘 자체보다 데이터를 어떻게 나누고 검증했는지에 더 크게 좌우된다. 잘못된 데이터 분할은 과적합을 발견하지 못하고 모델 성능을 과대평가하게 만든다. 이 장에서는 올바른 데이터 분할 방법과 교차 검증 기법을 학습한다.
예제: 데이터 로드
import seaborn as snsimport pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom sklearn.model_selection import train_test_split# 데이터 로드df = sns.load_dataset("penguins")df_ml = df.dropna()print("데이터 크기:", df_ml.shape)print("\n타겟 변수 분포:")print(df_ml["species"].value_counts())
데이터 크기: (333, 7)
타겟 변수 분포:
species
Adelie 146
Gentoo 119
Chinstrap 68
Name: count, dtype: int64
19.1 데이터 분할의 필요성
머신러닝 모델은 학습 데이터에 최적화되므로, 동일한 데이터로 평가하면 성능이 과대평가된다.
과적합과 일반화
개념
설명
문제점
과적합 (Overfitting)
학습 데이터에 지나치게 최적화
새로운 데이터에서 성능 저하
과소적합 (Underfitting)
학습 데이터조차 제대로 학습 못함
전반적으로 낮은 성능
일반화 (Generalization)
보지 못한 데이터에도 잘 작동
목표
데이터 분할의 목적
일반화 성능 평가: 모델이 새로운 데이터에서 얼마나 잘 작동하는가?
과적합 탐지: 학습 성능과 검증 성능의 차이 확인
모델 선택: 여러 모델 중 가장 좋은 모델 선택
하이퍼파라미터 튜닝: 최적의 설정값 찾기
공정한 비교: 동일한 기준으로 모델 성능 비교
잘못된 평가의 예
# ❌ 잘못된 예: 학습 데이터로 평가model.fit(X, y)score = model.score(X, y) # 과대평가!# ✓ 올바른 예: 별도의 테스트 데이터로 평가X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)model.fit(X_train, y_train)score = model.score(X_test, y_test) # 올바른 평가
특성 행렬(X) 크기: (333, 4)
타겟 벡터(y) 크기: (333,)
타겟 클래스 분포:
species
Adelie 146
Gentoo 119
Chinstrap 68
Name: count, dtype: int64
클래스 비율:
species
Adelie 0.438
Gentoo 0.357
Chinstrap 0.204
Name: count, dtype: float64
예제: 학습/테스트 분할
# 학습/테스트 분할 (80/20)X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2, # 테스트 20% random_state=42, # 재현성 stratify=y # 클래스 비율 유지)print("=== 데이터 분할 결과 ===")print(f"전체 데이터: {len(X)}")print(f"학습 데이터: {len(X_train)} ({len(X_train)/len(X)*100:.1f}%)")print(f"테스트 데이터: {len(X_test)} ({len(X_test)/len(X)*100:.1f}%)")# 클래스 비율 확인print("\n=== 클래스 비율 비교 ===")print("전체 데이터:")print((y.value_counts() /len(y)).round(3))print("\n학습 데이터:")print((y_train.value_counts() /len(y_train)).round(3))print("\n테스트 데이터:")print((y_test.value_counts() /len(y_test)).round(3))
=== 데이터 분할 결과 ===
전체 데이터: 333
학습 데이터: 266 (79.9%)
테스트 데이터: 67 (20.1%)
=== 클래스 비율 비교 ===
전체 데이터:
species
Adelie 0.438
Gentoo 0.357
Chinstrap 0.204
Name: count, dtype: float64
학습 데이터:
species
Adelie 0.440
Gentoo 0.357
Chinstrap 0.203
Name: count, dtype: float64
테스트 데이터:
species
Adelie 0.433
Gentoo 0.358
Chinstrap 0.209
Name: count, dtype: float64
train_test_split 주요 파라미터
파라미터
설명
권장값
test_size
테스트셋 비율
0.2 ~ 0.3
random_state
난수 시드 (재현성)
고정값 (예: 42)
stratify
클래스 비율 유지
분류 문제에서 y
shuffle
섞기 여부
True (기본값)
19.3.2 학습/검증/테스트 분할
하이퍼파라미터 튜닝이 필요한 경우 3-way 분할을 수행한다.
예제: 3-way 분할
# 1단계: 학습+검증 vs 테스트 (80/20)X_temp, X_test, y_temp, y_test = train_test_split( X, y, test_size=0.2, random_state=42, stratify=y)# 2단계: 학습 vs 검증 (60/20)# temp의 25%는 전체의 20% (0.8 * 0.25 = 0.2)X_train, X_val, y_train, y_val = train_test_split( X_temp, y_temp, test_size=0.25, # temp의 25% = 전체의 20% random_state=42, stratify=y_temp)print("=== 3-way 데이터 분할 결과 ===")print(f"전체 데이터: {len(X)}")print(f"학습 데이터: {len(X_train)} ({len(X_train)/len(X)*100:.1f}%)")print(f"검증 데이터: {len(X_val)} ({len(X_val)/len(X)*100:.1f}%)")print(f"테스트 데이터: {len(X_test)} ({len(X_test)/len(X)*100:.1f}%)")# 시각화sizes = [len(X_train), len(X_val), len(X_test)]labels = ['Train (60%)', 'Validation (20%)', 'Test (20%)']colors = ['#3498db', '#2ecc71', '#e74c3c']plt.figure(figsize=(10, 6))plt.pie(sizes, labels=labels, colors=colors, autopct='%1.1f%%', startangle=90)plt.title("Data Split: Train/Validation/Test")plt.axis('equal')plt.show()
=== 3-way 데이터 분할 결과 ===
전체 데이터: 333
학습 데이터: 199 (59.8%)
검증 데이터: 67 (20.1%)
테스트 데이터: 67 (20.1%)
3-way 분할 사용 흐름
학습 데이터 (Train)
↓
모델 학습 (fit)
↓
검증 데이터 (Validation)
↓
하이퍼파라미터 튜닝
↓
최종 모델 선택
↓
테스트 데이터 (Test)
↓
최종 성능 평가 (단 한 번!)
19.4 교차 검증 (Cross-Validation)
교차 검증은 데이터를 여러 번 나누어 학습과 검증을 반복함으로써 더 안정적이고 신뢰할 수 있는 성능 추정을 제공한다.
교차 검증의 장점
장점
설명
안정적 평가
단일 분할의 운(luck)에 의존하지 않음
데이터 효율성
모든 데이터를 학습과 검증에 사용
분산 추정
성능의 평균과 표준편차 확인 가능
과적합 탐지
폴드 간 성능 차이로 과적합 감지
교차 검증 vs 홀드아웃
항목
홀드아웃 (단일 분할)
교차 검증
계산 비용
낮음
높음 (k배)
안정성
낮음 (운에 좌우)
높음
데이터 효율
낮음
높음 (모든 데이터 활용)
성능 분산
알 수 없음
측정 가능
소표본 적합성
부적합
적합
사용 시점
빠른 실험
최종 평가
19.5 K-Fold 교차 검증
K-Fold는 데이터를 K개의 폴드로 나누어 각 폴드를 한 번씩 검증셋으로 사용하는 방법이다.
K-Fold 원리
전체 데이터를 K개로 분할
Fold 1: [Validation] [Train] [Train] [Train] [Train]
Fold 2: [Train] [Validation] [Train] [Train] [Train]
Fold 3: [Train] [Train] [Validation] [Train] [Train]
Fold 4: [Train] [Train] [Train] [Validation] [Train]
Fold 5: [Train] [Train] [Train] [Train] [Validation]
→ K번 학습 후 평균 성능 계산
Stratified K-Fold는 각 폴드에서 클래스 비율을 유지하는 K-Fold의 변형으로, 불균형 데이터에서 필수적이다.
왜 필요한가?
일반 K-Fold는 클래스를 고려하지 않으므로: - 한 폴드에 특정 클래스가 몰릴 수 있음 - 폴드 간 성능 차이가 클래스 불균형 때문일 수 있음 - 소수 클래스가 일부 폴드에 없을 수 있음
예제: Stratified K-Fold
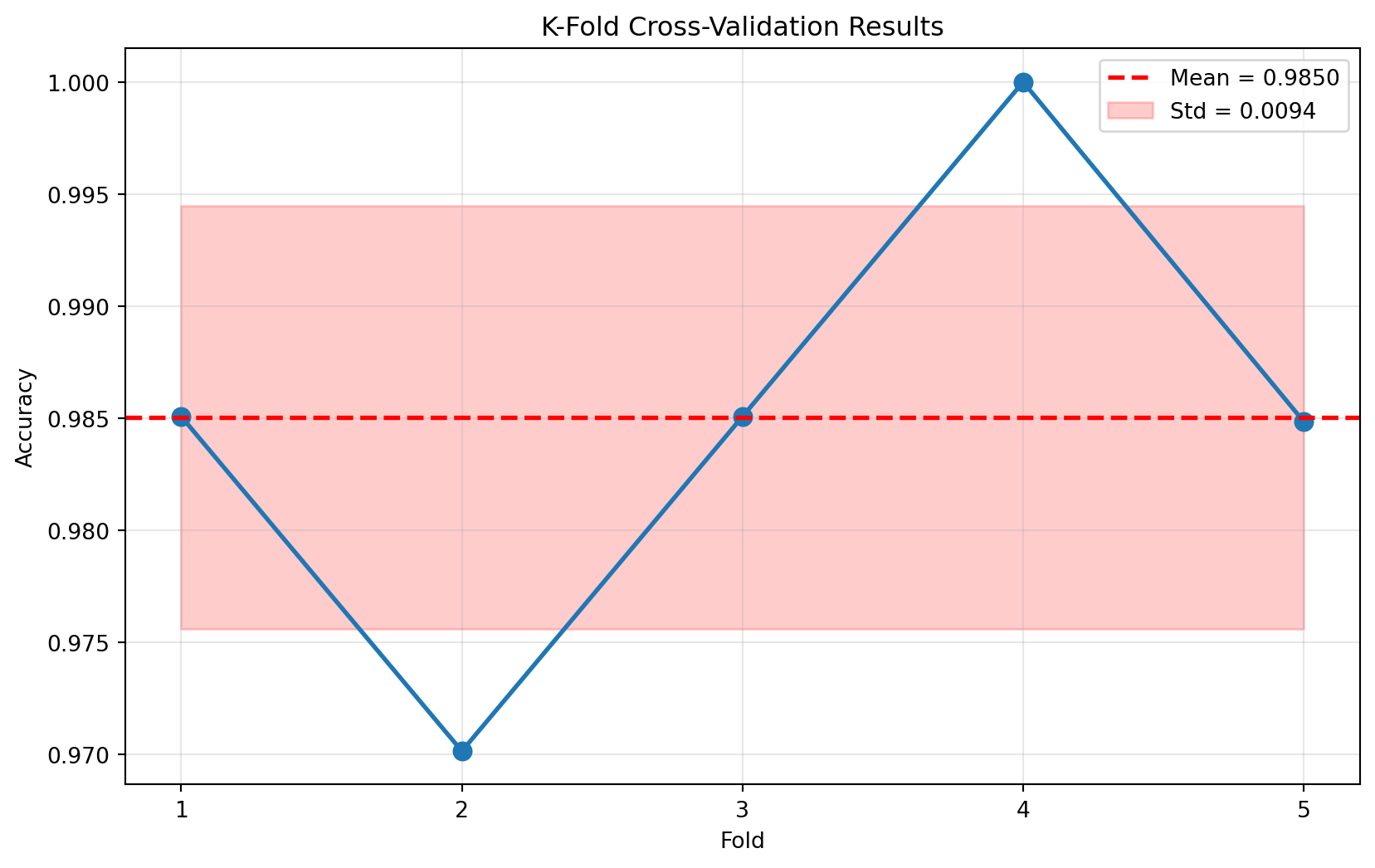
from sklearn.model_selection import StratifiedKFold# Stratified K-Fold 설정skf = StratifiedKFold( n_splits=5, shuffle=True, random_state=42)# 교차 검증 수행scores_stratified = cross_val_score( model, X, y, cv=skf, scoring='accuracy')print("=== Stratified K-Fold 교차 검증 결과 ===")print(f"각 폴드 정확도: {scores_stratified}")print(f"평균 정확도: {scores_stratified.mean():.4f}")print(f"표준편차: {scores_stratified.std():.4f}")# K-Fold vs Stratified K-Fold 비교print("\n=== K-Fold vs Stratified K-Fold 비교 ===")print(f"K-Fold: 평균 = {scores.mean():.4f}, 표준편차 = {scores.std():.4f}")print(f"Stratified K-Fold: 평균 = {scores_stratified.mean():.4f}, 표준편차 = {scores_stratified.std():.4f}")
=== Stratified K-Fold 교차 검증 결과 ===
각 폴드 정확도: [0.97014925 0.98507463 0.98507463 1. 0.98484848]
평균 정확도: 0.9850
표준편차: 0.0094
=== K-Fold vs Stratified K-Fold 비교 ===
K-Fold: 평균 = 0.9850, 표준편차 = 0.0094
Stratified K-Fold: 평균 = 0.9850, 표준편차 = 0.0094
예제: 폴드별 클래스 분포 확인
# 폴드별 클래스 분포 확인print("\n=== 각 폴드의 클래스 분포 ===")for fold_idx, (train_idx, val_idx) inenumerate(skf.split(X, y), 1): y_fold = y.iloc[val_idx]print(f"\nFold {fold_idx}:")print(f" 크기: {len(y_fold)}")print(f" 클래스 비율:")print((y_fold.value_counts() /len(y_fold)).round(3).to_dict())
=== 각 폴드의 클래스 분포 ===
Fold 1:
크기: 67
클래스 비율:
{'Adelie': 0.448, 'Gentoo': 0.358, 'Chinstrap': 0.194}
Fold 2:
크기: 67
클래스 비율:
{'Adelie': 0.433, 'Gentoo': 0.358, 'Chinstrap': 0.209}
Fold 3:
크기: 67
클래스 비율:
{'Adelie': 0.433, 'Gentoo': 0.358, 'Chinstrap': 0.209}
Fold 4:
크기: 66
클래스 비율:
{'Adelie': 0.439, 'Gentoo': 0.348, 'Chinstrap': 0.212}
Fold 5:
크기: 66
클래스 비율:
{'Adelie': 0.439, 'Gentoo': 0.364, 'Chinstrap': 0.197}
19.7 기타 교차 검증 방법
교차 검증 방법 비교
방법
설명
사용 상황
K-Fold
데이터를 K개로 분할
회귀, 균형 분류
Stratified K-Fold
클래스 비율 유지
불균형 분류 (권장)
Leave-One-Out (LOO)
K = n (각 샘플을 검증셋으로)
매우 소량 데이터
Leave-P-Out (LPO)
P개씩 조합
극소량 데이터
Shuffle Split
무작위 분할 반복
빠른 근사 평가
Group K-Fold
그룹 단위 분할
그룹 종속 데이터
Time Series Split
시간 순서 유지
시계열 데이터
19.7.1 Time Series Split (시계열 교차 검증)
시계열 데이터는 미래를 예측하므로, 학습 데이터가 검증 데이터보다 과거여야 한다.
예제: Time Series Split
from sklearn.model_selection import TimeSeriesSplit# Time Series Split 설정tscv = TimeSeriesSplit(n_splits=5)# 분할 시각화print("=== Time Series Split 구조 ===")for fold_idx, (train_idx, val_idx) inenumerate(tscv.split(X), 1):print(f"Fold {fold_idx}:")print(f" Train: {min(train_idx):3d} ~ {max(train_idx):3d} (n={len(train_idx)})")print(f" Val: {min(val_idx):3d} ~ {max(val_idx):3d} (n={len(val_idx)})")
분류 문제?
├─ Yes → 클래스 불균형?
│ ├─ Yes → Stratified K-Fold (필수)
│ └─ No → K-Fold 또는 Stratified K-Fold
└─ No (회귀) → 시계열?
├─ Yes → TimeSeriesSplit
└─ No → K-Fold
K 값 선택
데이터 크기
권장 K
이유
n < 100
k = n (LOO)
데이터 최대 활용
100 ≤ n < 1000
k = 10
표준, 계산 가능
n ≥ 1000
k = 5
계산 효율성
n ≥ 10000
k = 3 또는 홀드아웃
빠른 평가
19.9 데이터 누수 (Data Leakage) 방지
데이터 누수는 학습 과정에서 테스트 정보가 유입되어 성능이 과대평가되는 현상이다.
데이터 누수의 원인
원인
예시
올바른 방법
전처리 순서 오류
전체 데이터 스케일링 후 분할
분할 후 학습 데이터로만 스케일링
피처 선택 오류
전체 데이터로 피처 선택
분할 후 학습 데이터로만 선택
타겟 인코딩 오류
전체 데이터로 타겟 인코딩
분할 후 학습 데이터로만 인코딩
검증셋 재사용
검증셋으로 여러 번 튜닝
최종은 테스트셋으로 단 한 번
올바른 파이프라인
# ✓ 올바른 예: 분할 후 전처리from sklearn.pipeline import Pipelinefrom sklearn.preprocessing import StandardScaler# 1. 데이터 분할X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)# 2. 파이프라인 (분할 후 전처리)pipeline = Pipeline([ ('scaler', StandardScaler()), # 학습 데이터로만 fit ('model', LogisticRegression())])# 3. 학습 (scaler는 X_train으로만 fit됨)pipeline.fit(X_train, y_train)# 4. 평가 (scaler 파라미터는 학습 때 학습됨)score = pipeline.score(X_test, y_test)
19.10 요약
이 장에서는 데이터 분할과 교차 검증을 학습했다. 주요 내용은 다음과 같다.
데이터 분할 핵심
목적: 일반화 성능 평가, 과적합 탐지
기본 분할: Train/Validation/Test (60/20/20)
Stratify: 분류 문제에서 클래스 비율 유지 필수
테스트셋: 단 한 번만 사용 (최종 평가)
교차 검증 핵심
K-Fold: 데이터를 K개로 나누어 반복 평가
Stratified K-Fold: 분류 문제에서 권장 (클래스 비율 유지)
Time Series Split: 시계열 데이터 전용
장점: 안정적 평가, 모든 데이터 활용
실무 체크리스트
주의사항
테스트셋은 절대 학습에 사용하지 않음
전처리(스케일링 등)는 분할 후 수행
검증셋을 여러 번 보면 간접적인 과적합
시계열은 반드시 TimeSeriesSplit 사용
올바른 데이터 분할과 검증은 신뢰할 수 있는 모델 평가의 기초이다. 다음 장에서는 모델 성능을 측정하는 다양한 평가 지표를 학습할 것이다.