python, 전처리, 통계, 가설검정, 기계학습, 회귀, 분류, 군집, 모델 학습, 모델 평가
회귀 모델(Regression Models)은 입력 변수(X)와 연속형 타겟 변수(y) 사이의 관계를 학습하여 새로운 입력에 대한 수치값을 예측하는 지도 학습 모델이다. 예측 대상이 범주가 아닌 수치이며, 관계를 수학적 함수 형태로 모델링한다. 이 장에서는 선형 회귀부터 정규화 회귀(Ridge, Lasso, ElasticNet)까지 주요 회귀 모델의 원리와 실무 활용법을 학습한다.
예제: 데이터 로드
import seaborn as snsimport pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import StandardScalerfrom sklearn.metrics import mean_squared_error, r2_score, mean_absolute_error# 데이터 로드df = sns.load_dataset("penguins").dropna()# 특성과 타겟 준비X = df[["bill_length_mm", "bill_depth_mm", "flipper_length_mm"]]y = df["body_mass_g"]print("데이터 크기:", df.shape)print("\n특성 변수:", X.columns.tolist())print("타겟 변수: body_mass_g (연속형)")print(f"\n타겟 범위: {y.min():.0f}g ~ {y.max():.0f}g")
데이터 크기: (333, 7)
특성 변수: ['bill_length_mm', 'bill_depth_mm', 'flipper_length_mm']
타겟 변수: body_mass_g (연속형)
타겟 범위: 2700g ~ 6300g
22.1 회귀의 개념
회귀는 입력 변수와 출력 변수 간의 관계를 모델링하여 예측하는 기법이다.
회귀 vs 분류
구분
회귀 (Regression)
분류 (Classification)
출력 타입
연속형 (수치)
범주형 (클래스)
예측값
실수 값
클래스 라벨 또는 확률
예시
체중, 가격, 온도
종, 합격/불합격, 질병 유무
평가 지표
MSE, MAE, R²
정확도, 정밀도, 재현율
대표 모델
선형 회귀, Ridge, Lasso
로지스틱 회귀, 결정 트리
회귀 문제의 예
분야
입력 변수
출력 변수
부동산
면적, 방 개수, 위치
주택 가격
의료
나이, BMI, 혈압
혈당 수치
마케팅
광고비, 계절, 프로모션
매출액
생물학
부리 길이, 날개 길이
체중
22.2 데이터 준비 및 분할
예제: 학습/테스트 분할
# 데이터 분할X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2, random_state=42)print("=== 데이터 분할 ===")print(f"학습 데이터: {X_train.shape}")print(f"테스트 데이터: {X_test.shape}")# 타겟 분포 확인print("\n=== 타겟 분포 ===")print(f"학습셋 평균: {y_train.mean():.2f}g, 표준편차: {y_train.std():.2f}g")print(f"테스트셋 평균: {y_test.mean():.2f}g, 표준편차: {y_test.std():.2f}g")
=== 데이터 분할 ===
학습 데이터: (266, 3)
테스트 데이터: (67, 3)
=== 타겟 분포 ===
학습셋 평균: 4214.76g, 표준편차: 807.92g
테스트셋 평균: 4176.49g, 표준편차: 799.68g
22.3 선형 회귀 (Linear Regression)
선형 회귀는 입력 변수와 출력 변수 사이의 관계를 선형 결합으로 표현하는 가장 기본적인 회귀 모델이다.
여기서: - \(y\): 타겟 변수 - \(x_i\): 입력 변수 - \(\beta_0\): 절편 (intercept) - \(\beta_i\): 회귀 계수 (coefficient) - \(\varepsilon\): 오차항
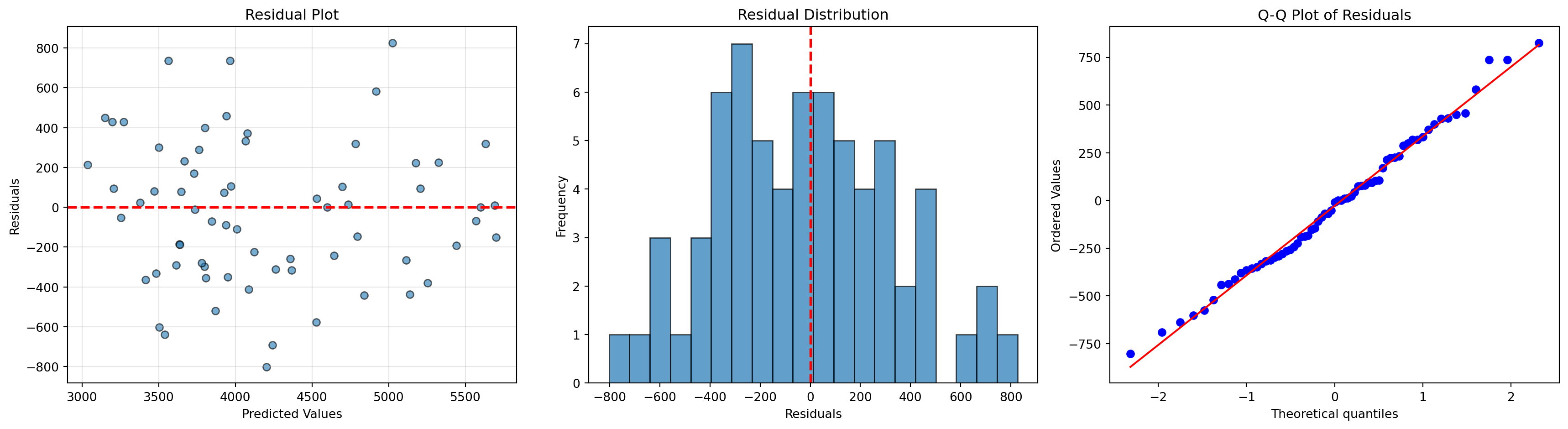
선형 회귀의 가정
가정
설명
확인 방법
선형성
X와 y가 선형 관계
잔차 플롯
독립성
관측치들이 서로 독립
실험 설계 확인
등분산성
오차의 분산이 일정
잔차 플롯
정규성
오차가 정규분포를 따름
Q-Q plot, 히스토그램
다중공선성 없음
독립변수들이 서로 독립
VIF, 상관행렬
현실에서는 완벽히 만족하지 않는 경우가 많지만, 어느 정도 근사하면 사용 가능하다.
22.3.1 선형 회귀 실습
예제: 선형 회귀 학습
from sklearn.linear_model import LinearRegression# 모델 생성 및 학습lr = LinearRegression()lr.fit(X_train, y_train)# 모델 파라미터 확인print("=== 선형 회귀 계수 ===")coef_df = pd.DataFrame({'Feature': X.columns,'Coefficient': lr.coef_}).sort_values('Coefficient', key=abs, ascending=False)print(coef_df)print(f"\n절편 (intercept): {lr.intercept_:.2f}")# 예측y_pred_train = lr.predict(X_train)y_pred_test = lr.predict(X_test)# 평가print("\n=== 모델 성능 ===")print(f"학습 R²: {r2_score(y_train, y_pred_train):.4f}")print(f"테스트 R²: {r2_score(y_test, y_pred_test):.4f}")print(f"테스트 RMSE: {np.sqrt(mean_squared_error(y_test, y_pred_test)):.2f}g")print(f"테스트 MAE: {mean_absolute_error(y_test, y_pred_test):.2f}g")
=== 선형 회귀 계수 ===
Feature Coefficient
2 flipper_length_mm 50.247255
1 bill_depth_mm 10.058133
0 bill_length_mm 3.857683
절편 (intercept): -6227.69
=== 모델 성능 ===
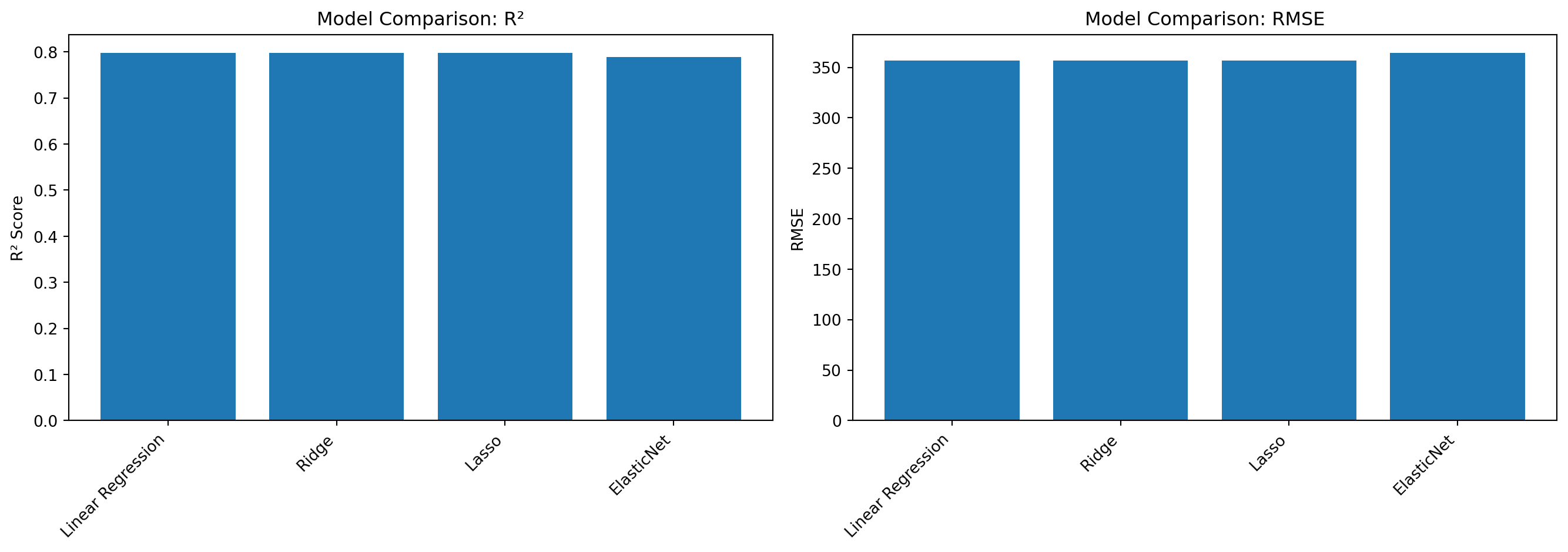
학습 R²: 0.7551
테스트 R²: 0.7981
테스트 RMSE: 356.65g
테스트 MAE: 289.69g
# 예측 vs 실제값 플롯plt.figure(figsize=(10, 6))plt.scatter(y_test, y_pred_test, alpha=0.6, edgecolors='k')plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], 'r--', linewidth=2, label='Perfect Prediction')plt.xlabel('Actual Body Mass (g)')plt.ylabel('Predicted Body Mass (g)')plt.title('Linear Regression: Actual vs Predicted')plt.legend()plt.grid(True, alpha=0.3)plt.tight_layout()plt.show()# 상관계수corr = np.corrcoef(y_test, y_pred_test)[0, 1]print(f"예측-실제 상관계수: {corr:.4f}")
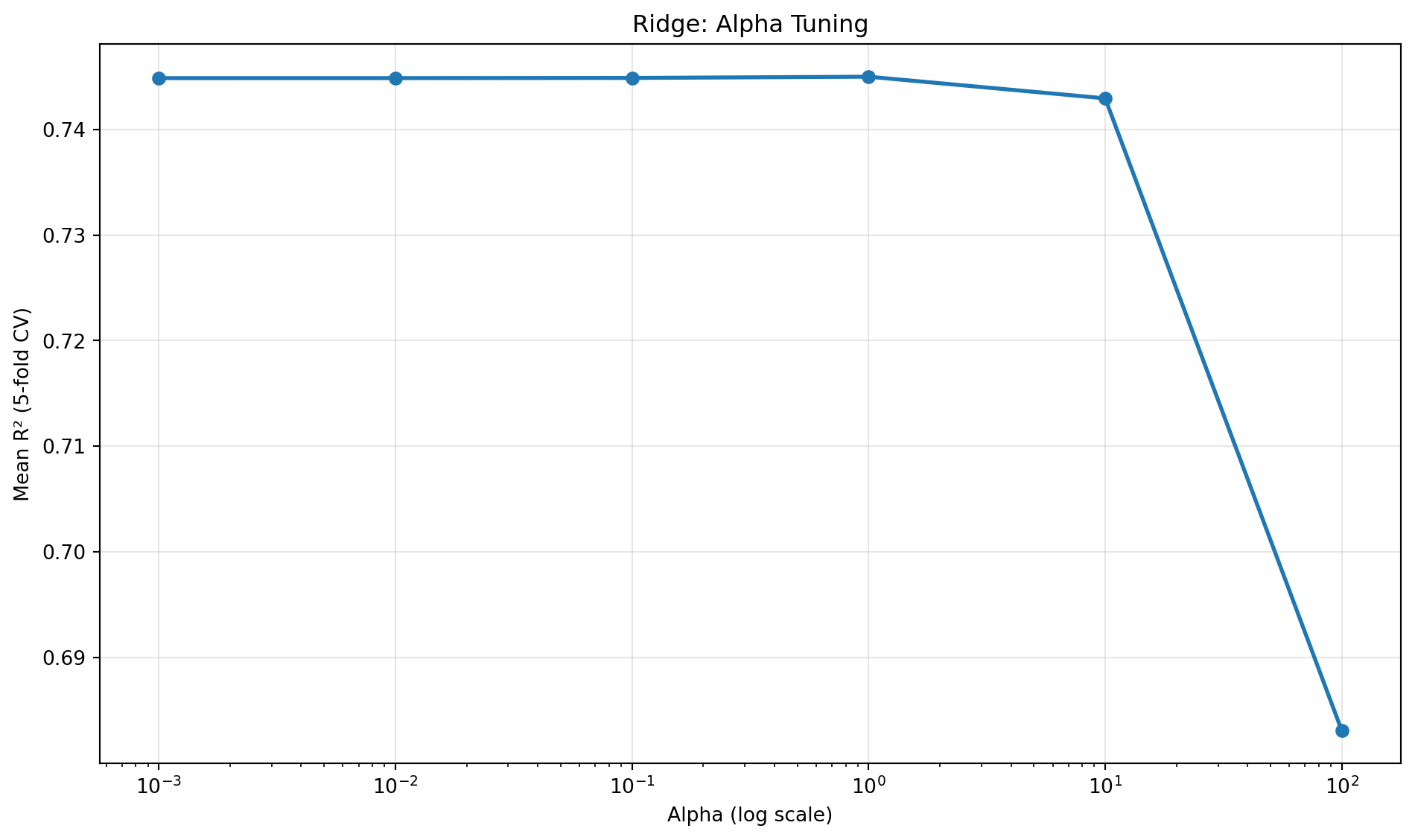
from sklearn.linear_model import Ridge# 데이터 표준화 (Ridge는 스케일에 민감)scaler = StandardScaler()X_train_scaled = scaler.fit_transform(X_train)X_test_scaled = scaler.transform(X_test)# Ridge 회귀ridge = Ridge(alpha=1.0)ridge.fit(X_train_scaled, y_train)# 계수 비교print("=== Ridge vs 선형 회귀 계수 비교 ===")comparison_df = pd.DataFrame({'Feature': X.columns,'Linear Regression': lr.coef_,'Ridge (α=1.0)': ridge.coef_})print(comparison_df.round(2))# 예측 및 평가y_pred_ridge = ridge.predict(X_test_scaled)print(f"\n=== Ridge 성능 ===")print(f"테스트 R²: {r2_score(y_test, y_pred_ridge):.4f}")print(f"테스트 RMSE: {np.sqrt(mean_squared_error(y_test, y_pred_ridge)):.2f}g")
=== Ridge vs 선형 회귀 계수 비교 ===
Feature Linear Regression Ridge (α=1.0)
0 bill_length_mm 3.86 24.89
1 bill_depth_mm 10.06 16.44
2 flipper_length_mm 50.25 690.57
=== Ridge 성능 ===
테스트 R²: 0.7977
테스트 RMSE: 356.98g
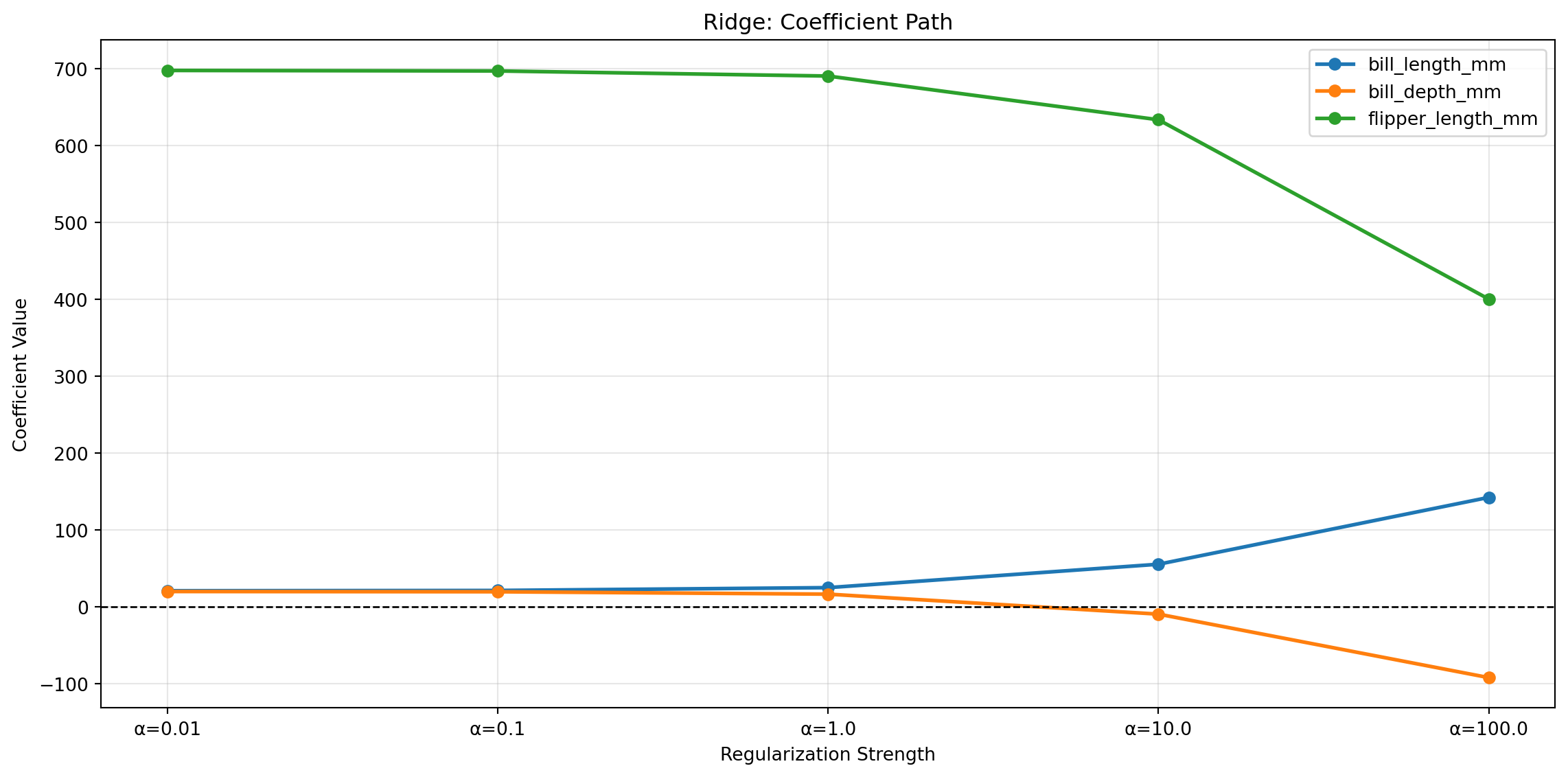
예제: Alpha 값에 따른 계수 변화
# 다양한 alpha 값으로 실험alphas = [0.01, 0.1, 1.0, 10.0, 100.0]coefs = []for alpha in alphas: ridge_temp = Ridge(alpha=alpha) ridge_temp.fit(X_train_scaled, y_train) coefs.append(ridge_temp.coef_)# 계수 변화 시각화coefs_df = pd.DataFrame(coefs, columns=X.columns, index=[f'α={a}'for a in alphas])plt.figure(figsize=(12, 6))for col in coefs_df.columns: plt.plot(range(len(alphas)), coefs_df[col], marker='o', label=col, linewidth=2)plt.xlabel('Regularization Strength')plt.ylabel('Coefficient Value')plt.title('Ridge: Coefficient Path')plt.xticks(range(len(alphas)), [f'α={a}'for a in alphas])plt.legend()plt.grid(True, alpha=0.3)plt.axhline(y=0, color='black', linestyle='--', linewidth=1)plt.tight_layout()plt.show()
22.6 Lasso 회귀 (L1 정규화)
Lasso 회귀는 계수의 절댓값 합(L1 norm)에 패널티를 부여하며, 일부 계수를 정확히 0으로 만든다.
from sklearn.linear_model import Lasso# Lasso 회귀lasso = Lasso(alpha=0.1)lasso.fit(X_train_scaled, y_train)# 계수 비교print("=== Lasso vs Ridge vs 선형 회귀 계수 비교 ===")comparison_df = pd.DataFrame({'Feature': X.columns,'Linear Regression': lr.coef_,'Ridge (α=1.0)': ridge.coef_,'Lasso (α=0.1)': lasso.coef_})print(comparison_df.round(2))# 0이 아닌 계수 개수n_nonzero = np.sum(lasso.coef_ !=0)print(f"\nLasso가 선택한 변수 수: {n_nonzero}/{len(X.columns)}")# 예측 및 평가y_pred_lasso = lasso.predict(X_test_scaled)print(f"\n=== Lasso 성능 ===")print(f"테스트 R²: {r2_score(y_test, y_pred_lasso):.4f}")print(f"테스트 RMSE: {np.sqrt(mean_squared_error(y_test, y_pred_lasso)):.2f}g")
=== Lasso vs Ridge vs 선형 회귀 계수 비교 ===
Feature Linear Regression Ridge (α=1.0) Lasso (α=0.1)
0 bill_length_mm 3.86 24.89 20.83
1 bill_depth_mm 10.06 16.44 19.63
2 flipper_length_mm 50.25 690.57 697.66
Lasso가 선택한 변수 수: 3/3
=== Lasso 성능 ===
테스트 R²: 0.7980
테스트 RMSE: 356.68g
예제: Lasso 변수 선택 시각화
# 다양한 alpha 값에서 변수 선택alphas_lasso = [0.01, 0.1, 1.0, 10.0, 50.0]coefs_lasso = []n_features = []for alpha in alphas_lasso: lasso_temp = Lasso(alpha=alpha, max_iter=10000) lasso_temp.fit(X_train_scaled, y_train) coefs_lasso.append(lasso_temp.coef_) n_features.append(np.sum(lasso_temp.coef_ !=0))# 계수 경로 시각화plt.figure(figsize=(12, 6))coefs_lasso_df = pd.DataFrame(coefs_lasso, columns=X.columns)for col in coefs_lasso_df.columns: plt.plot(range(len(alphas_lasso)), coefs_lasso_df[col], marker='o', label=col, linewidth=2)plt.xlabel('Regularization Strength')plt.ylabel('Coefficient Value')plt.title('Lasso: Coefficient Path (Automatic Feature Selection)')plt.xticks(range(len(alphas_lasso)), [f'α={a}\n({n}개 변수)'for a, n inzip(alphas_lasso, n_features)])plt.legend()plt.grid(True, alpha=0.3)plt.axhline(y=0, color='black', linestyle='--', linewidth=1)plt.tight_layout()plt.show()