python, 전처리, 통계, 가설검정, 기계학습, 회귀, 분류, 군집, 모델 학습, 모델 평가
군집 분석(Clustering)은 라벨이 없는 데이터에서 유사한 데이터끼리 자동으로 묶는 비지도 학습 기법이다. 정답이 주어지지 않은 상태에서 데이터의 내재된 구조를 발견하고 패턴을 파악하는 것이 목적이다. 군집 분석은 데이터 탐색, 세분화, 이상치 탐지, 전처리 등 다양한 분야에서 활용된다. 이 장에서는 K-Means, DBSCAN, GMM 등 주요 군집 알고리즘의 원리와 실무 활용법을 학습한다.
예제: 데이터 로드
import seaborn as snsimport pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom sklearn.preprocessing import StandardScalerfrom sklearn.decomposition import PCA# 데이터 로드df = sns.load_dataset("penguins").dropna()# 군집 분석용 특성 선택 (연속형 변수만)X_cluster = df[["bill_length_mm", "bill_depth_mm", "flipper_length_mm", "body_mass_g"]]# 실제 종 정보 (평가용)y_true = df["species"]print("데이터 크기:", X_cluster.shape)print("\n특성 변수:", X_cluster.columns.tolist())print("\n실제 종 분포:")print(y_true.value_counts())
데이터 크기: (333, 4)
특성 변수: ['bill_length_mm', 'bill_depth_mm', 'flipper_length_mm', 'body_mass_g']
실제 종 분포:
species
Adelie 146
Gentoo 119
Chinstrap 68
Name: count, dtype: int64
24.1 군집 분석의 개념
군집 분석은 비지도 학습으로, 타겟 변수 없이 데이터의 구조를 발견한다.
군집 분석 vs 분류
구분
군집 분석 (Clustering)
분류 (Classification)
학습 유형
비지도 학습
지도 학습
타겟
없음
있음 (라벨)
목적
구조 발견
예측
평가
내재적 지표, 시각화
정확도, F1 등
예시
고객 세분화, 패턴 발견
종 분류, 질병 진단
군집 분석의 목적
목적
설명
예시
데이터 탐색
구조와 패턴 파악
신규 데이터 이해
세분화
유사 그룹 생성
고객 세그먼트
이상치 탐지
군집에 속하지 않는 점 발견
이상 거래 탐지
전처리
군집을 새로운 특성으로 사용
군집 ID를 범주형 변수로
차원 축소 보조
시각화 전 그룹 파악
PCA + 군집
군집 분석의 가정
알고리즘마다 데이터에 대한 가정이 다르다.
알고리즘
가정
K-Means
구형(spherical) 군집, 유사한 크기
DBSCAN
밀도 기반 군집, 밀도 차이 적음
GMM
가우시안 분포 혼합
계층적 군집
트리 구조 가능
24.2 데이터 준비
예제: 데이터 표준화
# 표준화 (군집은 거리 기반이므로 필수)scaler = StandardScaler()X_scaled = scaler.fit_transform(X_cluster)print("=== 표준화 전후 비교 ===")print("원본 데이터 범위:")print(X_cluster.describe().loc[['min', 'max']])print("\n표준화 후 데이터 범위:")print(pd.DataFrame(X_scaled, columns=X_cluster.columns).describe().loc[['min', 'max']])
=== 표준화 전후 비교 ===
원본 데이터 범위:
bill_length_mm bill_depth_mm flipper_length_mm body_mass_g
min 32.1 13.1 172.0 2700.0
max 59.6 21.5 231.0 6300.0
표준화 후 데이터 범위:
bill_length_mm bill_depth_mm flipper_length_mm body_mass_g
min -2.177987 -2.067291 -2.069852 -1.874435
max 2.858227 2.204743 2.146028 2.603144
표준화의 중요성
거리 기반 알고리즘에서 필수
스케일이 큰 변수가 군집을 지배하는 것 방지
K-Means, DBSCAN에서 특히 중요
24.3 분할 기반 군집: K-Means
K-Means는 가장 널리 사용되는 군집 알고리즘으로, 데이터를 K개의 군집으로 분할한다.
K-Means 알고리즘 작동 원리
K개의 초기 중심점(centroid) 무작위 선택
각 데이터를 가장 가까운 중심점에 할당
각 군집의 중심점을 새로 계산 (평균)
중심점 변화가 없을 때까지 2-3 반복
K-Means 특징
특징
설명
군집 수
사전에 K 지정 필요
군집 형태
구형(spherical) 가정
계산 속도
빠름 (대용량 적합)
이상치 민감
평균 사용으로 민감
결정론적
초기값에 따라 결과 다름
하드 할당
각 데이터는 하나의 군집만
24.3.1 K-Means 실습
예제: K-Means 군집 분석
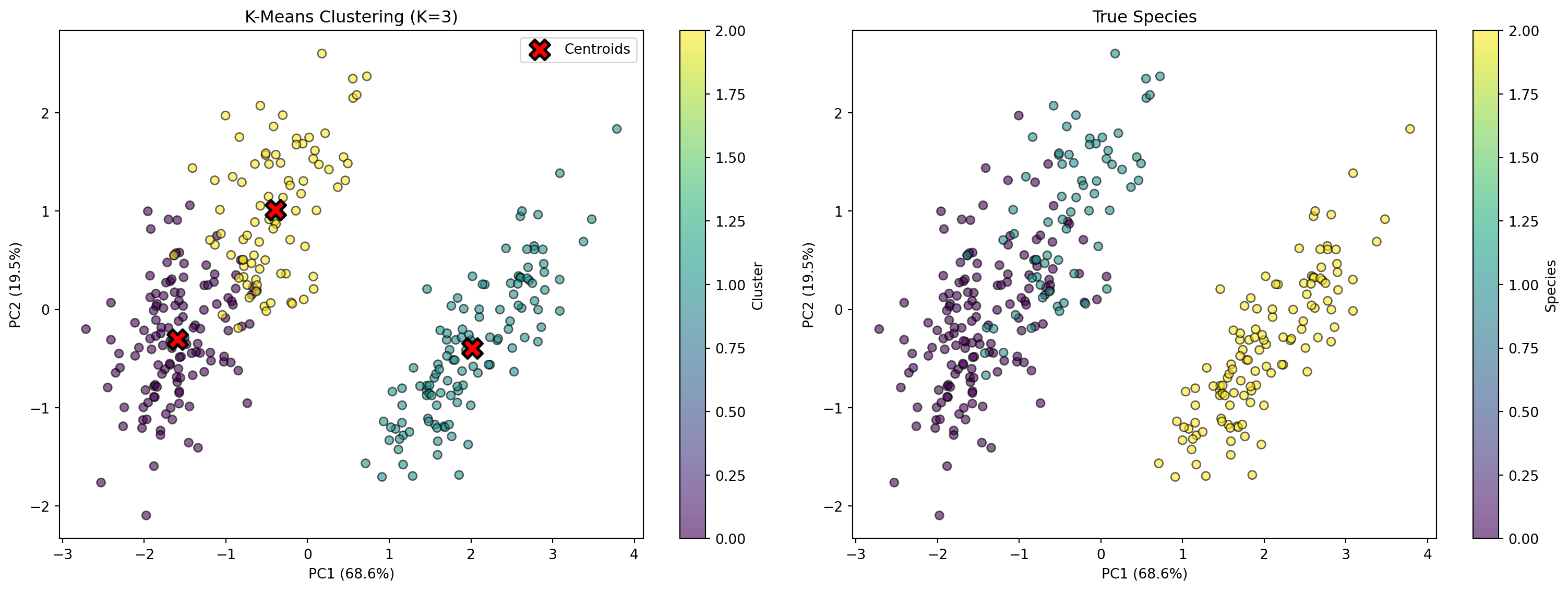
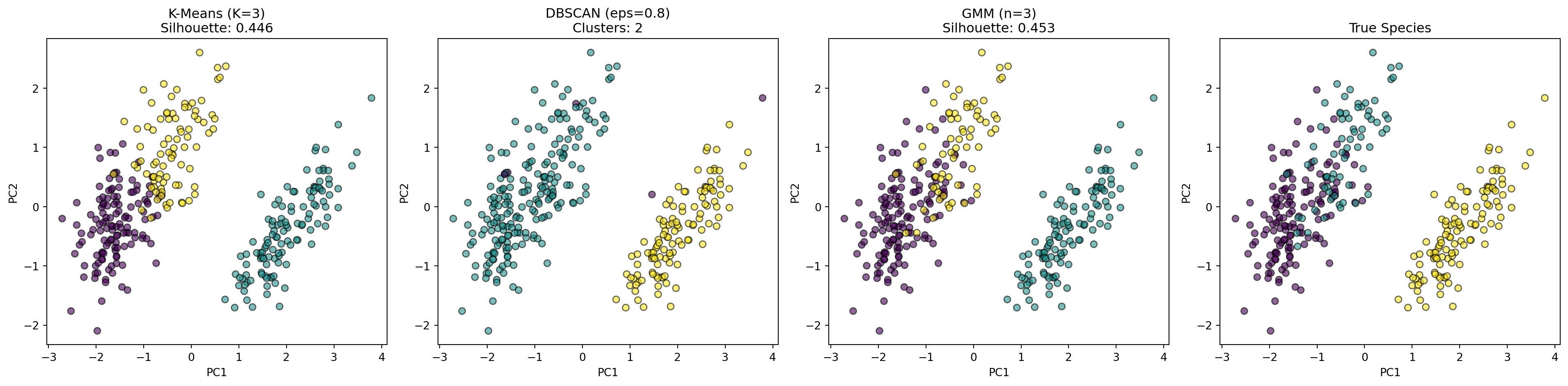
from sklearn.cluster import KMeans# K-Means 군집 (K=3, 실제 종 개수와 동일)kmeans = KMeans(n_clusters=3, random_state=42, n_init=10)labels_kmeans = kmeans.fit_predict(X_scaled)print("=== K-Means 결과 ===")print(f"군집 개수: {kmeans.n_clusters}")print(f"반복 횟수: {kmeans.n_iter_}")print("\n군집별 샘플 수:")print(pd.Series(labels_kmeans).value_counts().sort_index())# 실제 종과 비교comparison_df = pd.DataFrame({'True Species': y_true,'K-Means Cluster': labels_kmeans})print("\n=== 실제 종 vs 군집 ===")print(pd.crosstab(comparison_df['True Species'], comparison_df['K-Means Cluster']))
=== K-Means 결과 ===
군집 개수: 3
반복 횟수: 8
군집별 샘플 수:
0 129
1 119
2 85
Name: count, dtype: int64
=== 실제 종 vs 군집 ===
K-Means Cluster 0 1 2
True Species
Adelie 124 0 22
Chinstrap 5 0 63
Gentoo 0 119 0
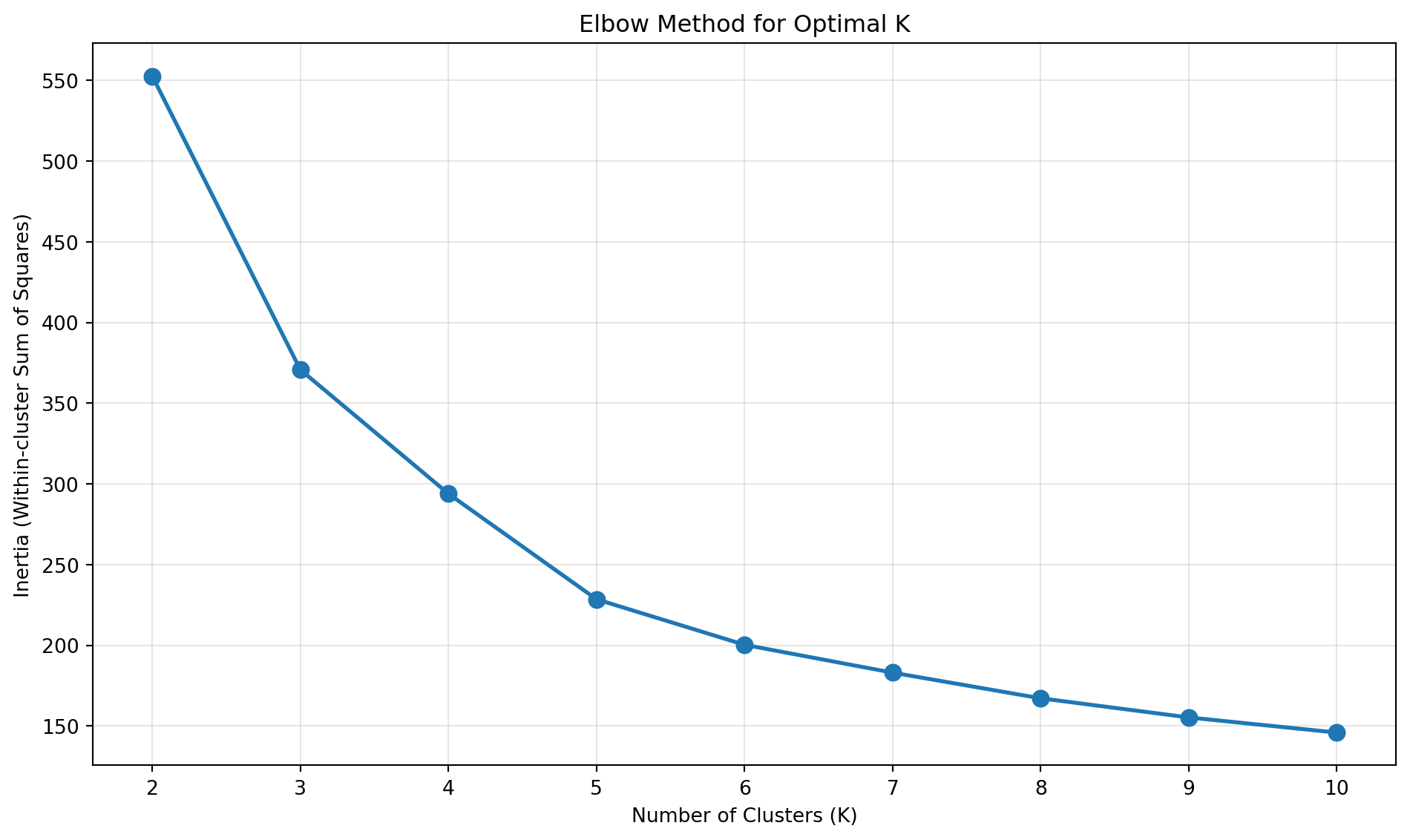
# 다양한 K 값으로 실험inertias = []K_range =range(2, 11)for k in K_range: kmeans_temp = KMeans(n_clusters=k, random_state=42, n_init=10) kmeans_temp.fit(X_scaled) inertias.append(kmeans_temp.inertia_)# Elbow Plotplt.figure(figsize=(10, 6))plt.plot(K_range, inertias, marker='o', linewidth=2, markersize=8)plt.xlabel('Number of Clusters (K)')plt.ylabel('Inertia (Within-cluster Sum of Squares)')plt.title('Elbow Method for Optimal K')plt.grid(True, alpha=0.3)plt.xticks(K_range)plt.tight_layout()plt.show()
방법 2: Silhouette Score
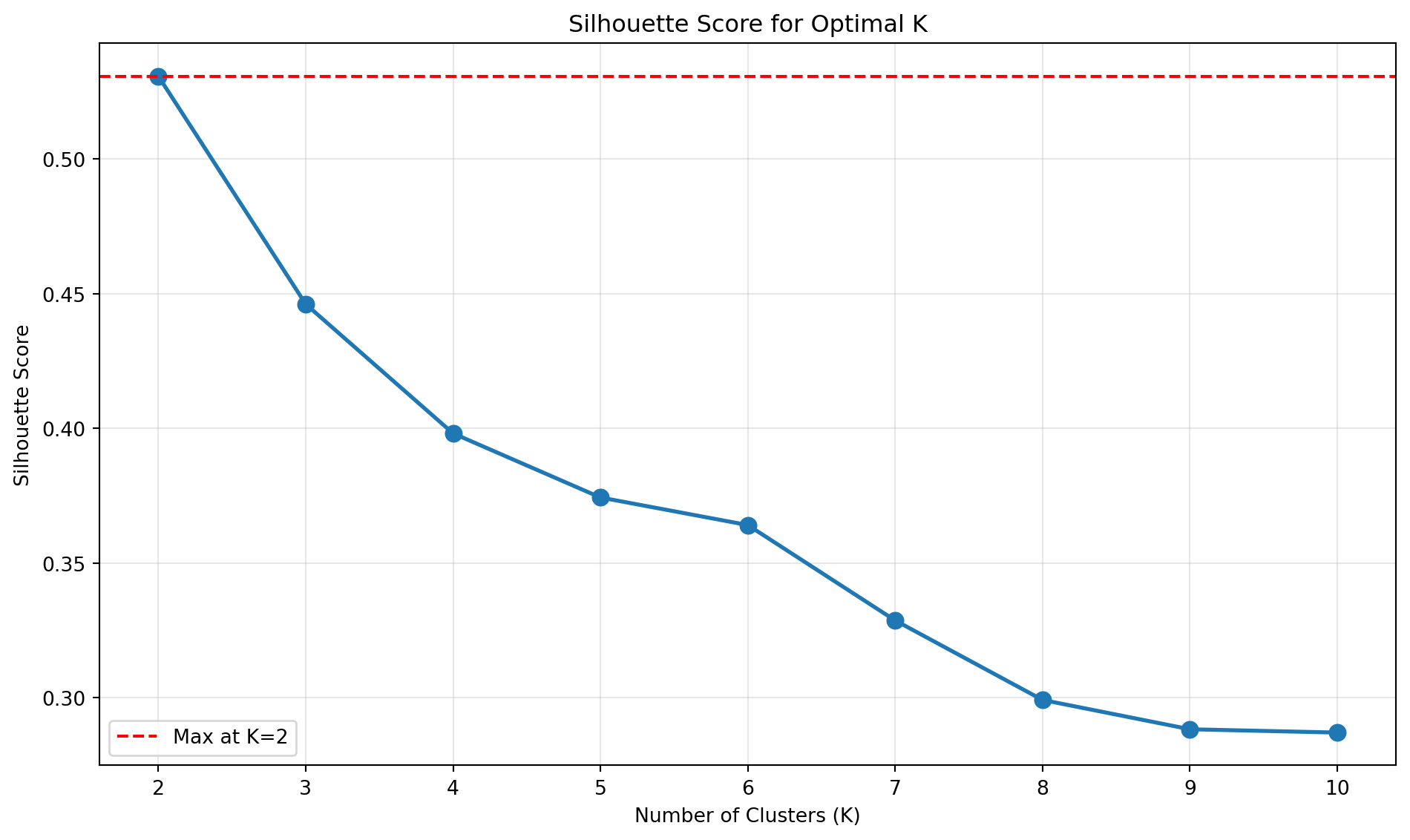
from sklearn.metrics import silhouette_score, silhouette_samples# Silhouette Score 계산silhouette_scores = []for k in K_range: kmeans_temp = KMeans(n_clusters=k, random_state=42, n_init=10) labels = kmeans_temp.fit_predict(X_scaled) score = silhouette_score(X_scaled, labels) silhouette_scores.append(score)# 시각화plt.figure(figsize=(10, 6))plt.plot(K_range, silhouette_scores, marker='o', linewidth=2, markersize=8)plt.xlabel('Number of Clusters (K)')plt.ylabel('Silhouette Score')plt.title('Silhouette Score for Optimal K')plt.grid(True, alpha=0.3)plt.axhline(y=np.max(silhouette_scores), color='r', linestyle='--', label=f'Max at K={K_range[np.argmax(silhouette_scores)]}')plt.legend()plt.xticks(K_range)plt.tight_layout()plt.show()print(f"최적 K (Silhouette): {K_range[np.argmax(silhouette_scores)]}")print(f"최대 Silhouette Score: {max(silhouette_scores):.4f}")