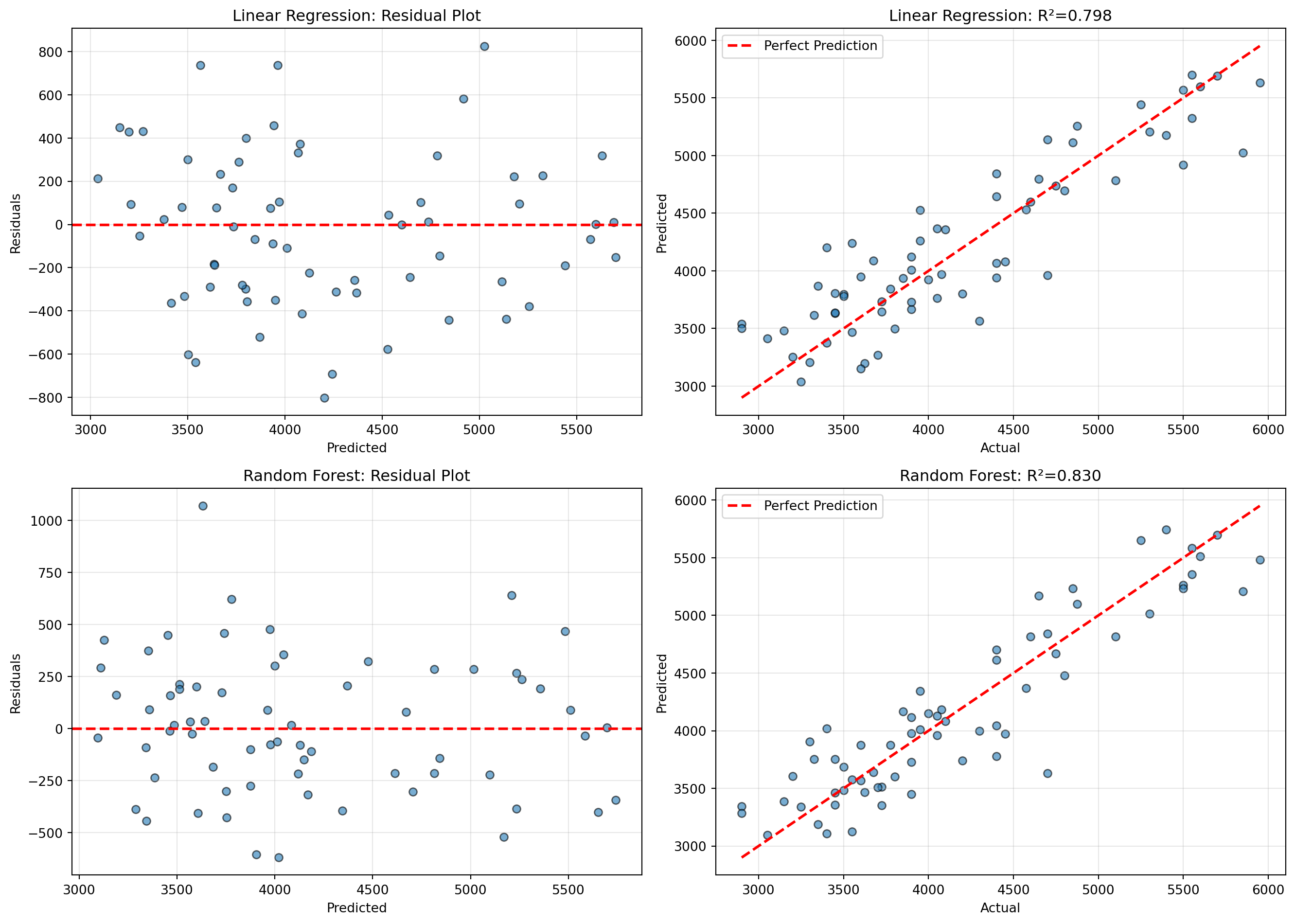
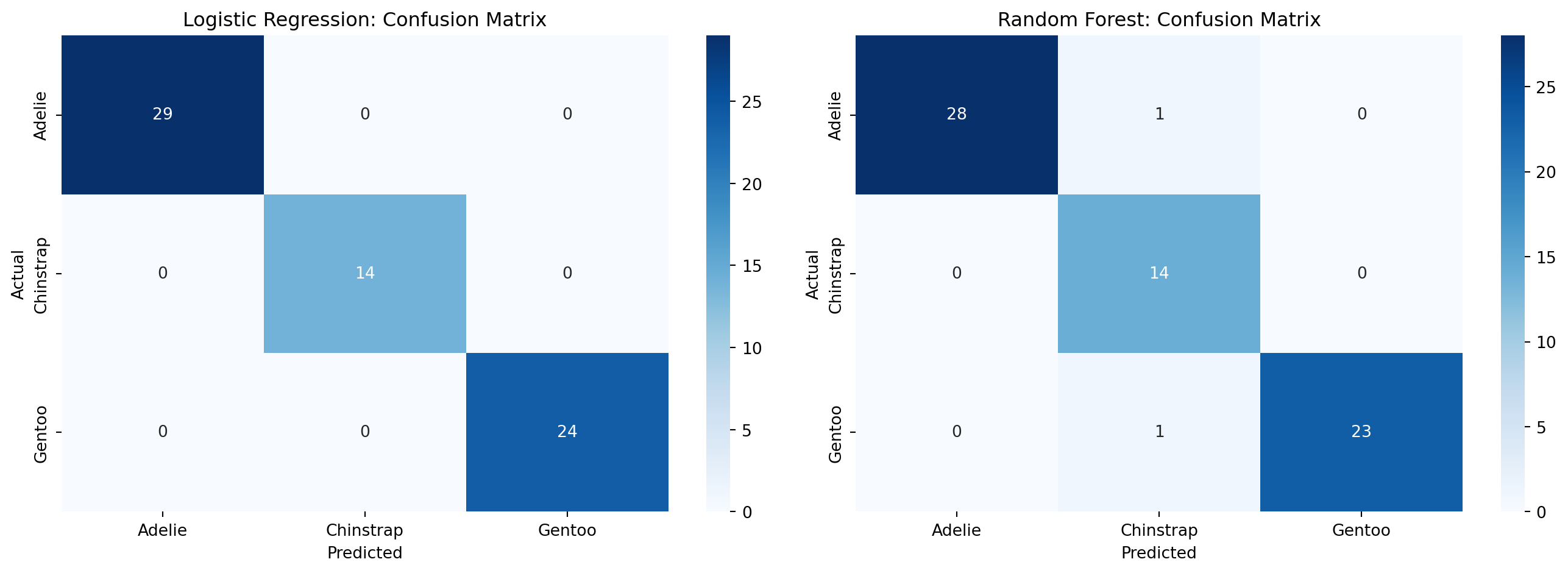
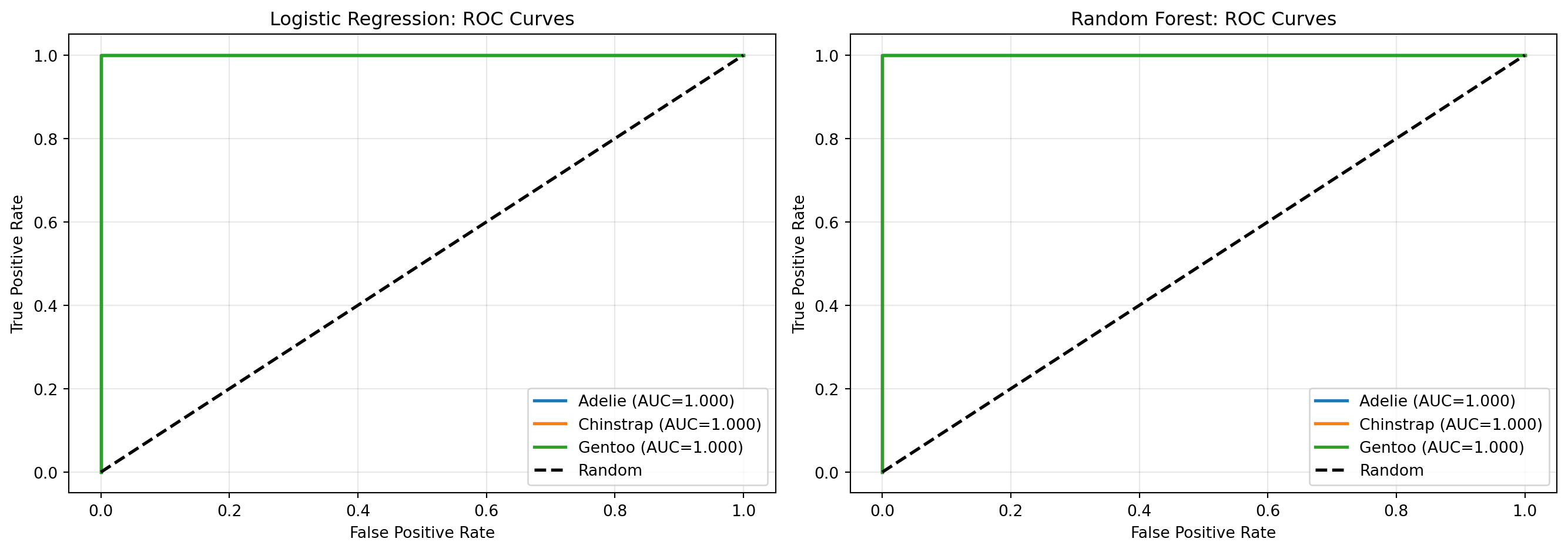
# 잔차 계산
residuals_lr = y_test_reg - y_pred_lr
residuals_rf = y_test_reg - y_pred_rf
# 시각화
fig, axes = plt.subplots(2, 2, figsize=(14, 10))
# Linear Regression 잔차
axes[0, 0].scatter(y_pred_lr, residuals_lr, alpha=0.6, edgecolors='k')
axes[0, 0].axhline(y=0, color='r', linestyle='--', linewidth=2)
axes[0, 0].set_xlabel('Predicted')
axes[0, 0].set_ylabel('Residuals')
axes[0, 0].set_title('Linear Regression: Residual Plot')
axes[0, 0].grid(True, alpha=0.3)
# Linear Regression 예측 vs 실제
axes[0, 1].scatter(y_test_reg, y_pred_lr, alpha=0.6, edgecolors='k')
axes[0, 1].plot([y_test_reg.min(), y_test_reg.max()],
[y_test_reg.min(), y_test_reg.max()],
'r--', linewidth=2, label='Perfect Prediction')
axes[0, 1].set_xlabel('Actual')
axes[0, 1].set_ylabel('Predicted')
axes[0, 1].set_title(f'Linear Regression: R²={r2_score(y_test_reg, y_pred_lr):.3f}')
axes[0, 1].legend()
axes[0, 1].grid(True, alpha=0.3)
# Random Forest 잔차
axes[1, 0].scatter(y_pred_rf, residuals_rf, alpha=0.6, edgecolors='k')
axes[1, 0].axhline(y=0, color='r', linestyle='--', linewidth=2)
axes[1, 0].set_xlabel('Predicted')
axes[1, 0].set_ylabel('Residuals')
axes[1, 0].set_title('Random Forest: Residual Plot')
axes[1, 0].grid(True, alpha=0.3)
# Random Forest 예측 vs 실제
axes[1, 1].scatter(y_test_reg, y_pred_rf, alpha=0.6, edgecolors='k')
axes[1, 1].plot([y_test_reg.min(), y_test_reg.max()],
[y_test_reg.min(), y_test_reg.max()],
'r--', linewidth=2, label='Perfect Prediction')
axes[1, 1].set_xlabel('Actual')
axes[1, 1].set_ylabel('Predicted')
axes[1, 1].set_title(f'Random Forest: R²={r2_score(y_test_reg, y_pred_rf):.3f}')
axes[1, 1].legend()
axes[1, 1].grid(True, alpha=0.3)
plt.tight_layout()
plt.show()