python, 전처리, 통계, 가설검정, 기계학습, 회귀, 분류, 군집, 모델 학습, 모델 평가
파이프라인(Pipeline)은 머신러닝 워크플로우의 전처리, 모델링, 평가 단계를 하나의 객체로 묶어 자동화하는 강력한 도구이다. 실무에서 가장 흔한 실수인 데이터 누수, 전처리 불일치, 재현 불가능한 실험을 구조적으로 방지한다. 파이프라인과 하이퍼파라미터 최적화(GridSearchCV, RandomizedSearchCV)를 결합하면 효율적이고 신뢰할 수 있는 머신러닝 워크플로우를 구축할 수 있다. 이 장에서는 파이프라인의 개념부터 실무 활용까지 체계적으로 학습한다.
예제: 데이터 로드
import seaborn as snsimport pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom sklearn.model_selection import train_test_split# 데이터 로드df = sns.load_dataset("penguins").dropna()# 특성과 타겟 준비X = df[["bill_length_mm", "bill_depth_mm", "flipper_length_mm", "body_mass_g", "sex"]]X['sex'] = (X['sex']=='Male')*1y = df["species"]# 데이터 분할X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2, random_state=42, stratify=y)print("데이터 크기:", X.shape)print("수치형 변수:", X.select_dtypes(include=[np.number]).columns.tolist())print("범주형 변수:", X.select_dtypes(exclude=[np.number]).columns.tolist())
from sklearn.preprocessing import StandardScalerfrom sklearn.linear_model import LogisticRegression# ❌ 잘못된 예: 파이프라인 없음# 전체 데이터 스케일링 (데이터 누수!)scaler_wrong = StandardScaler()X_scaled_wrong = scaler_wrong.fit_transform(X) # 테스트 데이터 정보 유출!# 데이터 분할X_train_wrong, X_test_wrong, y_train, y_test = train_test_split( X_scaled_wrong, y, test_size=0.2, random_state=42)# 모델 학습model_wrong = LogisticRegression(max_iter=1000)model_wrong.fit(X_train_wrong, y_train)acc_wrong = model_wrong.score(X_test_wrong, y_test)print("=== 잘못된 방법 (데이터 누수) ===")print(f"정확도: {acc_wrong:.4f}")print("⚠️ 과대평가 가능!")# ✓ 올바른 예: 파이프라인 사용from sklearn.pipeline import Pipelinepipe_correct = Pipeline([ ('scaler', StandardScaler()), ('model', LogisticRegression(max_iter=1000))])# 학습 (scaler는 X_train으로만 fit)pipe_correct.fit(X_train.select_dtypes(include=[np.number]), y_train)acc_correct = pipe_correct.score(X_test.select_dtypes(include=[np.number]), y_test)print("\n=== 올바른 방법 (파이프라인) ===")print(f"정확도: {acc_correct:.4f}")print("✓ 정확한 평가!")
=== 잘못된 방법 (데이터 누수) ===
정확도: 1.0000
⚠️ 과대평가 가능!
=== 올바른 방법 (파이프라인) ===
정확도: 0.3731
✓ 정확한 평가!
# 수치형 변수만 사용X_num = X.select_dtypes(include=[np.number])X_train_num, X_test_num, y_train, y_test = train_test_split( X_num, y, test_size=0.2, random_state=42, stratify=y)# 파이프라인 구성pipe_basic = Pipeline([ ('scaler', StandardScaler()), ('model', LogisticRegression(max_iter=1000, random_state=42))])# 학습pipe_basic.fit(X_train_num, y_train)# 평가train_score = pipe_basic.score(X_train_num, y_train)test_score = pipe_basic.score(X_test_num, y_test)print("=== 기본 파이프라인 성능 ===")print(f"학습 정확도: {train_score:.4f}")print(f"테스트 정확도: {test_score:.4f}")# 파이프라인 단계 확인print("\n=== 파이프라인 단계 ===")for name, step in pipe_basic.named_steps.items():print(f"{name}: {step}")
=== 기본 파이프라인 성능 ===
학습 정확도: 0.9962
테스트 정확도: 1.0000
=== 파이프라인 단계 ===
scaler: StandardScaler()
model: LogisticRegression(max_iter=1000, random_state=42)
예제: 파이프라인 내부 접근
# 특정 단계 접근scaler = pipe_basic.named_steps['scaler']model = pipe_basic.named_steps['model']print("\n=== Scaler 정보 ===")print(f"평균: {scaler.mean_[:3]}")print(f"표준편차: {scaler.scale_[:3]}")print("\n=== 모델 정보 ===")print(f"계수 shape: {model.coef_.shape}")print(f"클래스: {model.classes_}")
=== Scaler 정보 ===
평균: [ 43.98421053 17.22593985 201.30075188]
표준편차: [ 5.47311738 1.97054534 14.01475322]
=== 모델 정보 ===
계수 shape: (3, 5)
클래스: ['Adelie' 'Chinstrap' 'Gentoo']
27.3 ColumnTransformer: 혼합 데이터 처리
실제 데이터는 수치형과 범주형이 섞여 있어 각 타입별로 다른 전처리가 필요하다.
ColumnTransformer 개념
컬럼별로 다른 변환 적용
수치형: 스케일링
범주형: 인코딩
결과를 하나로 병합
27.3.1 ColumnTransformer 실습
예제: 수치형 + 범주형 전처리
from sklearn.compose import ColumnTransformerfrom sklearn.preprocessing import OneHotEncoder# 컬럼 타입 정의num_cols = ["bill_length_mm", "bill_depth_mm", "flipper_length_mm", "body_mass_g"]cat_cols = ["sex"]# ColumnTransformer 구성preprocessor = ColumnTransformer( transformers=[ ('num', StandardScaler(), num_cols), ('cat', OneHotEncoder(drop='first'), cat_cols) # drop='first'로 다중공선성 방지 ], remainder='drop'# 명시되지 않은 컬럼 제거)# 전체 파이프라인pipe_full = Pipeline([ ('preprocessor', preprocessor), ('model', LogisticRegression(max_iter=1000, random_state=42))])# 학습 및 평가pipe_full.fit(X_train, y_train)train_score_full = pipe_full.score(X_train, y_train)test_score_full = pipe_full.score(X_test, y_test)print("=== ColumnTransformer 파이프라인 성능 ===")print(f"학습 정확도: {train_score_full:.4f}")print(f"테스트 정확도: {test_score_full:.4f}")
=== ColumnTransformer 파이프라인 성능 ===
학습 정확도: 0.9925
테스트 정확도: 1.0000
예제: 변환된 특성 이름 확인
# 변환 후 특성 이름preprocessor_fitted = pipe_full.named_steps['preprocessor']# 수치형 특성 이름num_feature_names = num_cols# 범주형 특성 이름 (OneHotEncoder 후)cat_feature_names = preprocessor_fitted.named_transformers_['cat'].get_feature_names_out(cat_cols)# 전체 특성 이름all_feature_names =list(num_feature_names) +list(cat_feature_names)print("\n=== 변환 후 특성 이름 ===")print(f"수치형 ({len(num_feature_names)}개): {num_feature_names}")print(f"범주형 ({len(cat_feature_names)}개): {list(cat_feature_names)}")print(f"전체 ({len(all_feature_names)}개): {all_feature_names}")
=== 변환 후 특성 이름 ===
수치형 (4개): ['bill_length_mm', 'bill_depth_mm', 'flipper_length_mm', 'body_mass_g']
범주형 (1개): ['sex_1']
전체 (5개): ['bill_length_mm', 'bill_depth_mm', 'flipper_length_mm', 'body_mass_g', 'sex_1']
27.4 하이퍼파라미터 최적화
모델 성능은 하이퍼파라미터 설정에 크게 좌우된다. 자동 탐색이 필수이다.
하이퍼파라미터 탐색 방법 비교
방법
전략
탐색 범위
계산 비용
사용 상황
수동 조정
사람이 직접
제한적
낮음
소규모 실험
GridSearchCV
격자 탐색 (모든 조합)
지정한 값만
높음
작은 파라미터 공간
RandomizedSearchCV
무작위 샘플링
연속 분포 가능
중간
큰 파라미터 공간
Bayesian Optimization
확률 모델 기반
효율적 탐색
중간
복잡한 탐색
27.5 GridSearchCV: 격자 탐색
GridSearchCV는 지정한 모든 파라미터 조합을 빠짐없이 탐색한다.
GridSearchCV 특징
완전 탐색 (Exhaustive Search)
모든 조합 시도
최적값 보장 (탐색 범위 내)
계산 비용 높음
27.5.1 GridSearchCV 실습
예제: GridSearchCV로 최적 파라미터 찾기
from sklearn.model_selection import GridSearchCV# 파라미터 그리드 정의param_grid = {'model__C': [0.01, 0.1, 1.0, 10.0],'model__penalty': ['l2'],'model__solver': ['lbfgs']}# GridSearchCV 설정grid_search = GridSearchCV( estimator=pipe_full, param_grid=param_grid, cv=5, scoring='accuracy', n_jobs=-1, # 병렬 처리 verbose=1, return_train_score=True)# 탐색 실행print("=== GridSearchCV 실행 중 ===")grid_search.fit(X_train, y_train)# 최적 파라미터print("\n=== GridSearchCV 결과 ===")print(f"최적 파라미터: {grid_search.best_params_}")print(f"최적 교차 검증 점수: {grid_search.best_score_:.4f}")print(f"테스트 점수: {grid_search.score(X_test, y_test):.4f}")# 탐색한 조합 수print(f"\n탐색한 조합 수: {len(grid_search.cv_results_['params'])}")
=== GridSearchCV 실행 중 ===
Fitting 5 folds for each of 4 candidates, totalling 20 fits
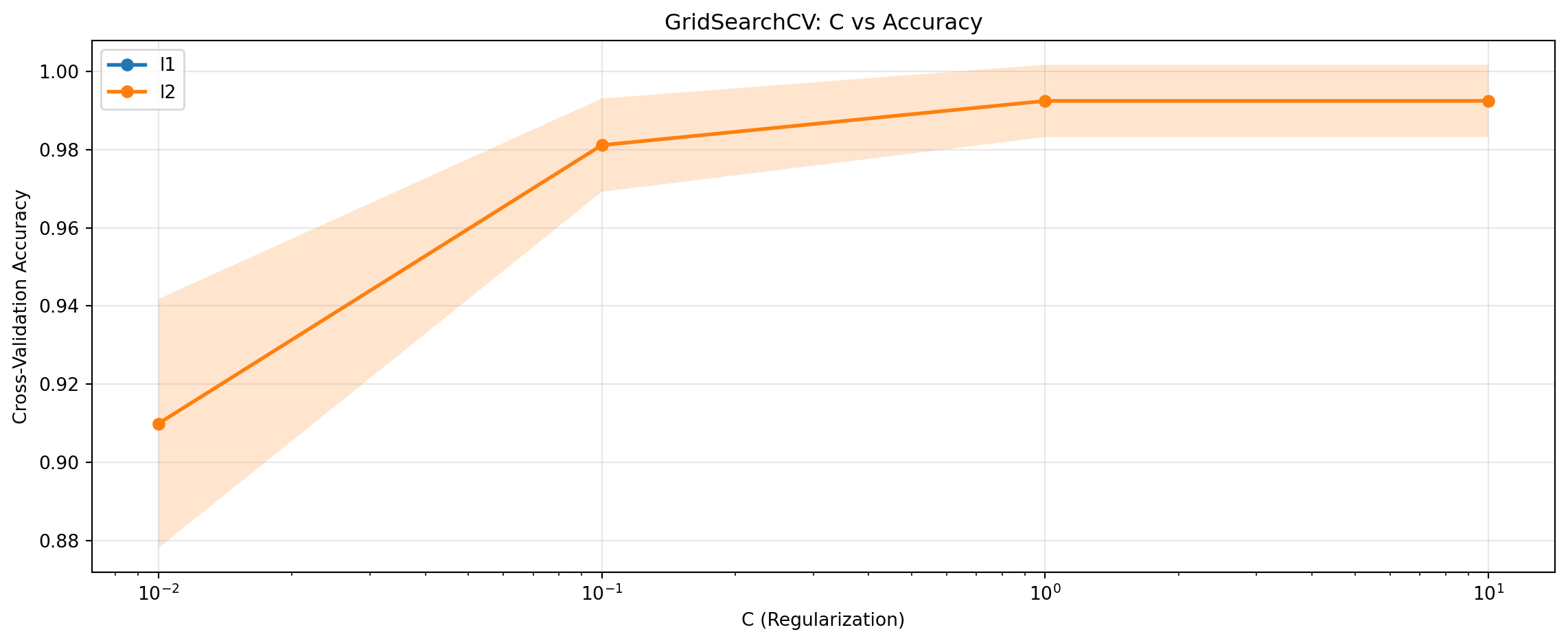
# 결과를 DataFrame으로 변환results_df = pd.DataFrame(grid_search.cv_results_)# C 값에 따른 성능plt.figure(figsize=(12, 5))for penalty in ['l1', 'l2']: mask = results_df['param_model__penalty'] == penalty subset = results_df[mask].sort_values('param_model__C') plt.plot(subset['param_model__C'], subset['mean_test_score'], marker='o', label=f'{penalty}', linewidth=2) plt.fill_between(subset['param_model__C'], subset['mean_test_score'] - subset['std_test_score'], subset['mean_test_score'] + subset['std_test_score'], alpha=0.2)plt.xscale('log')plt.xlabel('C (Regularization)')plt.ylabel('Cross-Validation Accuracy')plt.title('GridSearchCV: C vs Accuracy')plt.legend()plt.grid(True, alpha=0.3)plt.tight_layout()plt.show()
예제: 상위 5개 조합 확인
# 성능 상위 5개 조합top5 = results_df.nsmallest(5, 'rank_test_score')[ ['params', 'mean_test_score', 'std_test_score', 'rank_test_score']]print("\n=== 성능 상위 5개 조합 ===")for idx, row in top5.iterrows():print(f"순위 {int(row['rank_test_score'])}: {row['params']}")print(f" 평균 점수: {row['mean_test_score']:.4f} ± {row['std_test_score']:.4f}\n")
=== 성능 상위 5개 조합 ===
순위 1: {'model__C': 1.0, 'model__penalty': 'l2', 'model__solver': 'lbfgs'}
평균 점수: 0.9925 ± 0.0092
순위 1: {'model__C': 10.0, 'model__penalty': 'l2', 'model__solver': 'lbfgs'}
평균 점수: 0.9925 ± 0.0092
순위 3: {'model__C': 0.1, 'model__penalty': 'l2', 'model__solver': 'lbfgs'}
평균 점수: 0.9811 ± 0.0119
순위 4: {'model__C': 0.01, 'model__penalty': 'l2', 'model__solver': 'lbfgs'}
평균 점수: 0.9099 ± 0.0318
27.6 RandomizedSearchCV: 무작위 탐색
RandomizedSearchCV는 파라미터 공간에서 무작위로 샘플링하여 효율적으로 탐색한다.
RandomizedSearchCV 특징
무작위 샘플링
n_iter로 탐색 횟수 제어
연속 분포 사용 가능
GridSearchCV보다 빠름
27.6.1 RandomizedSearchCV 실습
예제: RandomizedSearchCV
from sklearn.model_selection import RandomizedSearchCVfrom scipy.stats import uniform, loguniform# 파라미터 분포 정의param_distributions = {'model__C': loguniform(1e-3, 1e2), # 로그 스케일'model__penalty': ['l2'],'model__solver': ['lbfgs']}# RandomizedSearchCV 설정random_search = RandomizedSearchCV( estimator=pipe_full, param_distributions=param_distributions, n_iter=20, # 20번 무작위 샘플링 cv=5, scoring='accuracy', n_jobs=-1, verbose=1, random_state=42, return_train_score=True)# 탐색 실행print("=== RandomizedSearchCV 실행 중 ===")random_search.fit(X_train, y_train)# 결과print("\n=== RandomizedSearchCV 결과 ===")print(f"최적 파라미터: {random_search.best_params_}")print(f"최적 교차 검증 점수: {random_search.best_score_:.4f}")print(f"테스트 점수: {random_search.score(X_test, y_test):.4f}")# Grid vs Random 비교print("\n=== GridSearchCV vs RandomizedSearchCV ===")print(f"Grid - 탐색 조합: {len(grid_search.cv_results_['params'])}, 최고 점수: {grid_search.best_score_:.4f}")print(f"Random - 탐색 조합: {len(random_search.cv_results_['params'])}, 최고 점수: {random_search.best_score_:.4f}")
=== RandomizedSearchCV 실행 중 ===
Fitting 5 folds for each of 20 candidates, totalling 100 fits
=== RandomizedSearchCV 결과 ===
최적 파라미터: {'model__C': np.float64(4.5705630998014515), 'model__penalty': 'l2', 'model__solver': 'lbfgs'}
최적 교차 검증 점수: 0.9925
테스트 점수: 1.0000
=== GridSearchCV vs RandomizedSearchCV ===
Grid - 탐색 조합: 4, 최고 점수: 0.9925
Random - 탐색 조합: 20, 최고 점수: 0.9925
27.7 교차 검증과 파이프라인의 결합
교차 검증 시 파이프라인을 사용하면 각 폴드마다 독립적으로 전처리가 수행되어 데이터 누수를 완전히 차단한다.
올바른 교차 검증 흐름
각 Fold에서:
1. 학습 데이터로 전처리 fit
2. 학습 데이터 transform
3. 검증 데이터 transform (학습 데이터의 파라미터 사용)
4. 모델 학습
5. 검증 데이터로 평가
예제: 교차 검증 with Pipeline
from sklearn.model_selection import cross_val_score, cross_validate# 교차 검증cv_scores = cross_val_score( pipe_full, X, y, cv=5, scoring='accuracy')print("=== 교차 검증 결과 ===")print(f"각 폴드 점수: {cv_scores}")print(f"평균 점수: {cv_scores.mean():.4f}")print(f"표준편차: {cv_scores.std():.4f}")# 여러 지표로 평가scoring = ['accuracy', 'precision_macro', 'recall_macro', 'f1_macro']cv_results = cross_validate( pipe_full, X, y, cv=5, scoring=scoring, return_train_score=True)print("\n=== 다중 지표 교차 검증 ===")for metric in scoring: test_scores = cv_results[f'test_{metric}']print(f"{metric:20s}: {test_scores.mean():.4f} ± {test_scores.std():.4f}")
from sklearn.ensemble import RandomForestClassifier# 1. 파이프라인 정의pipe_workflow = Pipeline([ ('preprocessor', ColumnTransformer([ ('num', StandardScaler(), num_cols), ('cat', OneHotEncoder(drop='first'), cat_cols) ])), ('model', RandomForestClassifier(random_state=42))])# 2. 하이퍼파라미터 그리드param_grid_rf = {'model__n_estimators': [50, 100, 200],'model__max_depth': [5, 10, None],'model__min_samples_split': [2, 5]}# 3. GridSearchCVgrid_rf = GridSearchCV( pipe_workflow, param_grid_rf, cv=5, scoring='f1_macro', n_jobs=-1, verbose=1)# 4. 학습print("=== 전체 워크플로우 실행 ===")grid_rf.fit(X_train, y_train)# 5. 최종 평가print("\n=== 최종 결과 ===")print(f"최적 파라미터: {grid_rf.best_params_}")print(f"교차 검증 F1 (macro): {grid_rf.best_score_:.4f}")print(f"테스트 F1 (macro): ", end="")from sklearn.metrics import f1_scorey_pred_final = grid_rf.predict(X_test)test_f1 = f1_score(y_test, y_pred_final, average='macro')print(f"{test_f1:.4f}")
=== 전체 워크플로우 실행 ===
Fitting 5 folds for each of 18 candidates, totalling 90 fits
=== 최종 결과 ===
최적 파라미터: {'model__max_depth': 5, 'model__min_samples_split': 2, 'model__n_estimators': 50}
교차 검증 F1 (macro): 0.9816
테스트 F1 (macro): 0.9827
27.9 모델 저장 및 로드
학습된 파이프라인은 저장하여 재사용할 수 있다.
예제: 모델 저장 및 로드
import joblib# 모델 저장model_filename ='best_pipeline.pkl'joblib.dump(grid_rf.best_estimator_, model_filename)print(f"\n모델 저장 완료: {model_filename}")# 모델 로드loaded_pipeline = joblib.load(model_filename)# 로드한 모델로 예측y_pred_loaded = loaded_pipeline.predict(X_test)accuracy_loaded = (y_pred_loaded == y_test).mean()print(f"\n=== 로드한 모델 성능 ===")print(f"정확도: {accuracy_loaded:.4f}")print("✓ 저장 전과 동일한 결과")
모델 저장 완료: best_pipeline.pkl
=== 로드한 모델 성능 ===
정확도: 0.9851
✓ 저장 전과 동일한 결과
27.10 실무 권장사항
파이프라인 사용 원칙
원칙
설명
이유
항상 파이프라인 사용
모든 실험을 파이프라인으로
데이터 누수 방지
전처리 통합
전처리를 파이프라인 안에
일관성 보장
CV 내부 전처리
교차 검증 전에 fit 안 함
독립성 유지
재현성 확보
random_state 고정
실험 재현 가능
적절한 scoring
문제에 맞는 지표
올바른 최적화
하이퍼파라미터 탐색 가이드
상황
방법
이유
파라미터 공간 작음
GridSearchCV
완전 탐색
파라미터 공간 큼
RandomizedSearchCV
효율성
시간 제약 있음
RandomizedSearchCV (적은 n_iter)
속도
연속 값 탐색
RandomizedSearchCV (분포 사용)
유연성
27.11 체크리스트
파이프라인 및 자동화 체크리스트
27.12 요약
이 장에서는 머신러닝 워크플로우를 자동화하는 파이프라인과 하이퍼파라미터 최적화를 학습했다. 주요 내용은 다음과 같다.
파이프라인 핵심
목적: 데이터 누수 방지, 코드 단순화, 재현성
구조: 전처리 → 모델 순차 실행
ColumnTransformer: 수치형/범주형 별도 처리
교차 검증: 각 폴드마다 독립적 전처리
하이퍼파라미터 최적화
GridSearchCV: 모든 조합 탐색 (작은 공간)
RandomizedSearchCV: 무작위 샘플링 (큰 공간)
교차 검증 통합: 과적합 방지
scoring: 문제에 맞는 지표 선택
실무 워크플로우
파이프라인 정의 (전처리 + 모델)
하이퍼파라미터 그리드 설정
GridSearchCV/RandomizedSearchCV 실행
최적 모델 선택
테스트 데이터로 최종 평가
모델 저장
파이프라인과 자동화는 신뢰할 수 있고 재현 가능한 머신러닝 프로젝트의 필수 요소이다. 모든 실험을 파이프라인으로 구성하고, 체계적인 하이퍼파라미터 탐색을 통해 최적의 모델을 찾는 것이 중요하다.