python, 전처리, 통계, 가설검정, 기계학습, 회귀, 분류, 군집, 모델 학습, 모델 평가
모델 해석(Model Interpretation)은 머신러닝 모델이 어떻게 예측하는지 이해하고 설명하는 과정이다. 모델이 복잡해질수록 블랙박스처럼 작동하지만, 실무에서는 “어떤 변수가 중요한가?”, “왜 이런 예측이 나왔는가?”, “모델이 편향되지 않았는가?”를 반드시 답해야 한다. 모델 해석은 선택이 아닌 필수이며, 신뢰성 있는 의사결정을 위해 반드시 필요하다. 이 장에서는 특성 중요도, Permutation Importance, SHAP, PDP 등 주요 모델 해석 기법을 학습한다.
예제: 데이터 로드
import seaborn as snsimport pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom sklearn.model_selection import train_test_splitfrom sklearn.ensemble import RandomForestClassifier# 데이터 로드df = sns.load_dataset("penguins").dropna()# 특성과 타겟 준비X = df[["bill_length_mm", "bill_depth_mm", "flipper_length_mm", "body_mass_g"]]y = df["species"]# 데이터 분할X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2, random_state=42, stratify=y)print("데이터 크기:", X.shape)print("특성:", X.columns.tolist())print("타겟:", y.name)
데이터 크기: (333, 4)
특성: ['bill_length_mm', 'bill_depth_mm', 'flipper_length_mm', 'body_mass_g']
타겟: species
28.1 모델 해석의 필요성
모델 해석은 단순한 학술적 관심이 아니라 실무적 필수 요소이다.
모델 해석이 필요한 이유
이유
설명
예시
신뢰성 확보
모델 결정 근거 제시
의료 진단, 대출 심사
편향 탐지
불공정한 예측 발견
성별/인종 차별 방지
디버깅
모델 오류 원인 파악
잘못된 변수 사용 발견
규제 준수
설명 가능성 요구 충족
GDPR, 금융 규제
도메인 지식 결합
전문가 검증 가능
의학적 타당성 확인
개선 방향
모델 성능 향상 힌트
중요 변수 추가 수집
해석 가능성 vs 성능
모델
해석 가능성
성능
사용 상황
선형 회귀
매우 높음
낮음
규제 산업, 보고서
결정 트리
높음
중간
비즈니스 룰
랜덤 포레스트
중간
높음
일반적 상황
XGBoost
낮음
매우 높음
경진대회
딥러닝
매우 낮음
매우 높음
이미지, 텍스트
28.2 모델 해석의 범주
모델 해석은 전역적 해석과 국소적 해석으로 나뉜다.
전역 해석 vs 국소 해석
구분
전역 해석 (Global)
국소 해석 (Local)
질문
모델이 전반적으로 무엇을 중요하게 보는가?
이 특정 예측은 왜 이렇게 나왔는가?
대상
전체 데이터셋
개별 샘플
방법
Feature Importance, PDP
SHAP Force Plot, LIME
용도
모델 이해, 변수 선택
개별 결정 설명
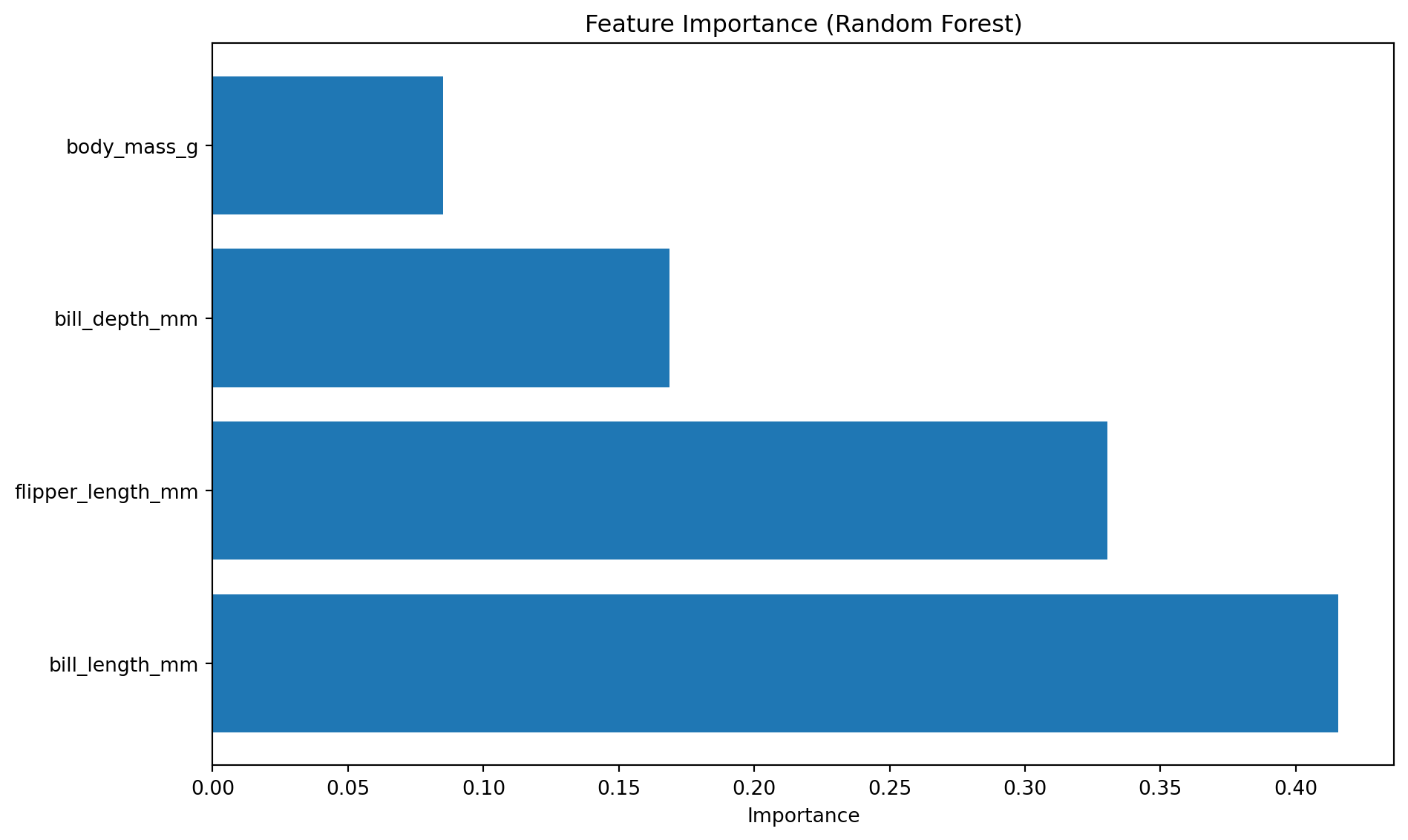
28.3 특성 중요도 (Feature Importance)
특성 중요도는 모델이 예측에 각 변수를 얼마나 활용했는지 수치로 표현한 것이다.
28.3.1 트리 기반 모델의 특성 중요도
트리 기반 모델(Decision Tree, Random Forest, XGBoost)은 내장 중요도를 제공한다.
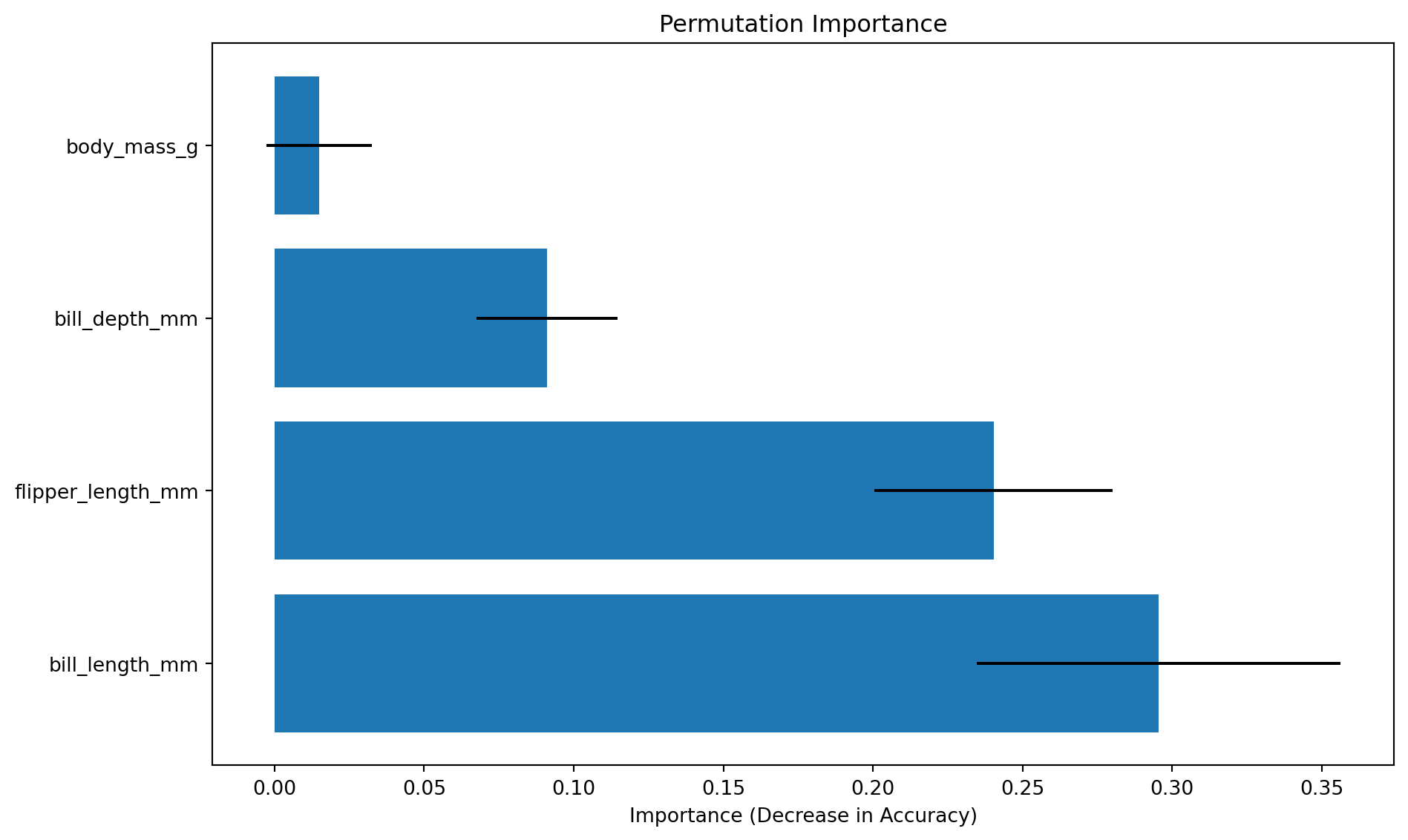
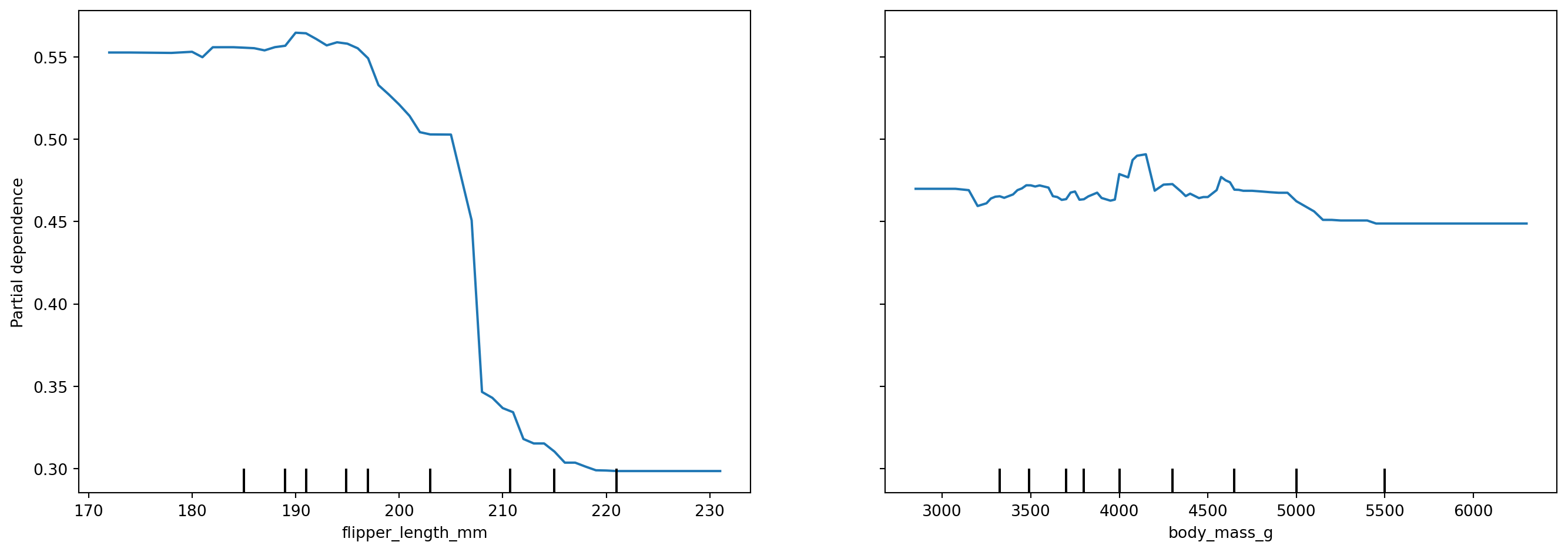
# 1. Permutation Importance로 중요 변수 파악print("=== 1. 중요 변수 파악 (Permutation Importance) ===")print(perm_importance.head(3))# 2. PDP로 상위 2개 변수 영향 확인print("\n=== 2. 변수 영향 방향 확인 (PDP) ===")top2_features = perm_importance.head(2)['Feature'].tolist()fig, ax = plt.subplots(figsize=(14, 5))PartialDependenceDisplay.from_estimator( rf, X_train, top2_features, target='Adelie', ax=ax)plt.suptitle('Top 2 Features: Partial Dependence')plt.tight_layout()plt.show()# 3. 모델 성능from sklearn.metrics import accuracy_score, classification_reporty_pred = rf.predict(X_test)accuracy = accuracy_score(y_test, y_pred)print("\n=== 3. 모델 성능 ===")print(f"정확도: {accuracy:.4f}")print("\n분류 리포트:")print(classification_report(y_test, y_pred))
=== 1. 중요 변수 파악 (Permutation Importance) ===
Feature Importance Std
0 bill_length_mm 0.295522 0.060737
2 flipper_length_mm 0.240299 0.039742
1 bill_depth_mm 0.091045 0.023552
=== 2. 변수 영향 방향 확인 (PDP) ===